10 deep learning methods that artificial intelligence practitioners have to know
The wave of artificial intelligence is sweeping the globe, and the field of research is expanding. The terms of deep learning and machine learning are around us. Many entrepreneurs want to work in the AI ​​industry, and deep learning is an important area of ​​learning.
Recently, software engineer James Le published an article entitled "The 10 Deep Learning Methods AI PracTITIoners Need to Apply" on Medium. From backpropagation to maximum pooling and finally to migration learning, he shared the main application in the text. Ten deep learning methods for convolutional neural networks, recurrent neural networks, and recurrent neural networks. The heart of the machine has compiled this article. The original link can be found at the end of the article.
Over the past decade, people’s interest in machine learning has not diminished. You see machine learning almost every day in computer science programs, industry conferences, and the Wall Street Journal. For all the discussion about machine learning, many people confuse what machine learning can do with what it is hoped for. Fundamentally, machine learning uses algorithms to extract information from raw data and implement it through models. We use this model to infer other data that we have not yet modeled.
Neural networks, a kind of machine learning model, have been around for more than 50 years, and their basic unit is a nonlinear transformation node inspired by biological neurons in the mammalian brain. The connections between neurons are also modeled after the biological brain and develop through training over time.
In the mid-1980s and early 1990s, significant advances were made to many important architectures of neural networks. However, the amount of time and data required to get good results has hampered its application, so people's interest has been greatly reduced. In the early 2000s, computing power grew exponentially, and the industry witnessed the "Cambrian explosion" of computing technology that was previously impossible. As an important competitor in this field, deep learning has stood out in this decade of explosive computing growth, and it has won many important machine learning competitions. The heat of deep learning peaks in 2017, and you can see deep learning in all areas of machine learning.
Below is the result of a job, a t-SNE projection of a word vector clustered by similarity.
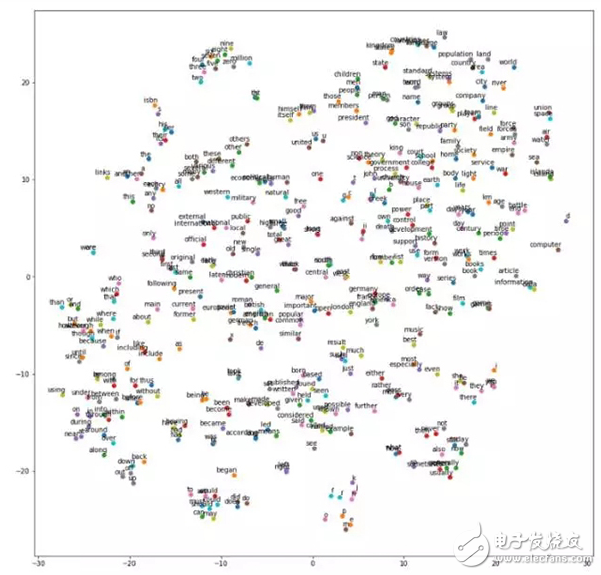
Recently, I have started reading related academic papers. According to my research, here are some books that have had a major impact on the development of the field:
New York University's "Gradient-Based Learning Applied to Document RecogniTIon" (1998) introduces the convolutional neural network in the field of machine learning: http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
The University of Toronto's "Deep Boltzmann Machines" (2009), which presents a new learning algorithm for multiple Boltzmann machines with multiple hidden variable layers: http://proceedings.mlr.press/v5/salakhutdinov09a/ Salakhutdinov09a.pdf
Stanford University and Google's "Building High-Level Features Using Large-Scale Unsupervised Learning" (2012), which solves the problem of constructing high-order, class-specific feature detectors from unlabeled data only: http://icml. Cc/2012/papers/73.pdf
Berkeley's "DeCAF-A Deep ConvoluTIonal Activation Feature for Generic Visual Recognition" (2013), which introduces DeCAF, a deep convolution activation feature and an open source implementation of all relevant network parameters, can help visual researchers in a range of visual concepts Deep characterization experiments in the learning paradigm: http://proceedings.mlr.press/v32/donahue14.pdf
DeepMind's "Playing Atari with Deep Reinforcement Learning" (2016), which demonstrates the first deep learning model for learning control strategies directly from high-dimensional perceptual input with reinforcement learning: https://~vmnih/docs/dqn.pdf
After researching and learning a lot of knowledge, I want to share 10 powerful deep learning methods that engineers can use to solve their own machine learning problems. Before we start, let's define what deep learning is. Deep learning is a challenge many people face because it has slowly changed its form over the past decade. In order to visually define deep learning, the following figure shows the relationship between artificial intelligence, machine learning and deep learning.
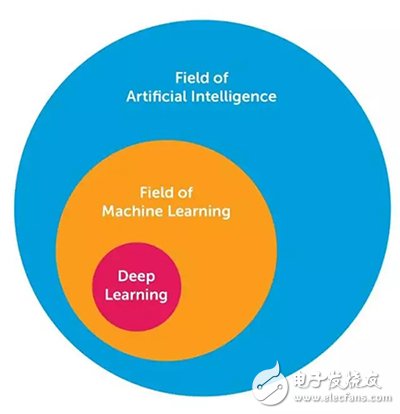
The field of artificial intelligence is the most extensive and has existed for 60+ years. Deep learning is a sub-area of ​​machine learning, and machine learning is a sub-area of ​​artificial intelligence. The reasons why deep learning is different from traditional feedforward multi-layer networks are usually the following:
More neurons
More complex connections between layers
Training the power of the "Cambrian explosion"
Automatic feature extraction
When I say "more neurons", I mean that the number of neurons grows year by year to express more complex models. Layers also evolve from each layer that is fully connected in a multi-layer network to a locally connected neuron patch between layers in a convolutional neural network, and to the same neuron in the recurrent neural network (except for connections to the previous layer) Periodic connection.
Deep learning can then be defined as a neural network with a large number of parameters and layers in one of the following four basic network architectures:
Unsupervised pre-training network
Convolutional neural network
Recurrent neural network
Recurrent neural network
This article will focus on the next three architectures. The convolutional neural network is basically a standard neural network that spreads across the space by sharing weights. The convolutional neural network is designed to recognize the image by internally convolving, and the edges of the object on the identified image can be seen. The cyclic neural network achieves an extension over time by feeding the edges to the next time step instead of going to the next layer in the same time step. Cyclic neural networks are designed to identify sequences, such as speech signals or text sequences, whose internal loops store short-term memory in the network. A recurrent neural network is more like a hierarchical network where the input sequence has no real time dimension, but the input must be layered in a tree-like manner. The following 10 methods can be used for all of the above architectures.
Back propagationBackpropagation is simply a method of calculating the partial derivative (or gradient) of a function (in the form of a composite function in a neural network). When using a gradient-based approach (gradient descent is just one of them) to solve the optimization problem, the gradient of the function needs to be calculated in each iteration.

In neural networks, the objective function is usually in the form of a composite function. How to calculate the gradient at this time? There are two ways: (i) Analytic differentiation, the form of the function is known, and the derivative can be calculated directly using the chain rule. (ii) Approximate differentiation using finite difference, which is computationally intensive because the number of function evaluation is equal to O(N), where N is the number of parameters. Compared to analytical differentiation, the amount of computation is much larger. Finite difference is usually used to verify the implementation of backpropagation during debugging.
2. Random gradient descentAn intuitive way to understand the gradient drop is to imagine a path down the river from the top of the mountain. The goal of gradient descent is exactly what the river strives to achieve—that is, to reach the lowest point (mountain foot).
Suppose the mountain's topography makes it unnecessary for the river to make any stops before reaching the lowest point (ideally, in machine learning it means reaching the global minimum/optimal solution from the initial point). However, there are also many pitted terrains that cause the river to stagnate in the middle of its path. In the terminology of machine learning, these pits are called local minima solutions and are situations that need to be avoided. There are many ways to solve this problem (not covered in this article).
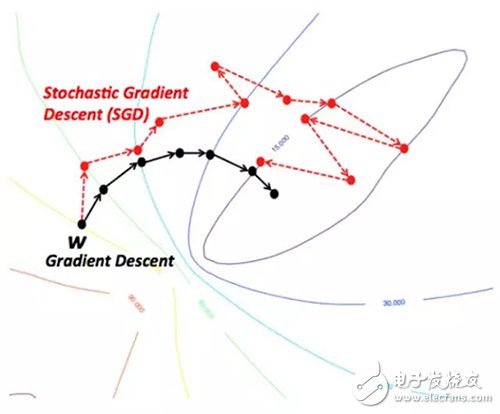
Therefore, the gradient descent tends to stagnate at the local minimum solution, depending on the nature of the terrain (or function in machine learning). However, when the topography of the mountain is a special type, that is, the bowl-shaped landform, which is called a convex function in machine learning, the algorithm can guarantee to find the optimal solution. Convex functions are the most wanted functions in machine learning optimization. Moreover, starting from different peaks (initial points), the path before reaching the lowest point is also different. Similarly, differences in the flow rate of the river (learning rate or step size in the gradient descent algorithm) also affect the shape of the path. These variables affect whether the gradient decline is trapped in a local optimal solution or avoided.
3. Learning rate attenuation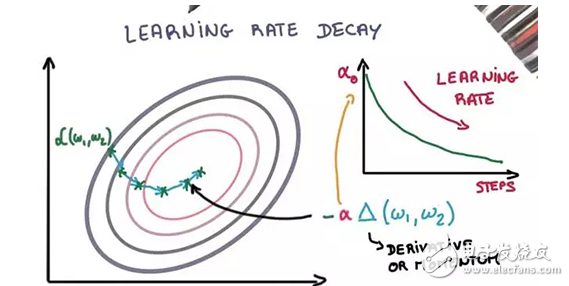
Adjusting the learning rate of the stochastic gradient descent optimization process can improve performance and reduce training time, called learning rate annealing (annealing) or adaptive learning rate. The simplest and probably the most commonly used learning rate adjustment technique is to reduce the learning rate over time. This is useful for making greater changes with a larger learning rate at the beginning of training, and for finer adjustments of weights at a later learning rate with a smaller learning rate.
Two simple and commonly used learning rate attenuation methods are as follows:
Decrease learning rate as epoch increases;
Reduce learning rates intermittently at specific epoch.
DropoutA deep neural network with a large number of parameters is a very powerful machine learning system. However, such networks have serious over-fitting problems. Moreover, large networks run very slowly, making the process of over-fitting by combining predictions from multiple different large neural networks in the testing phase also slow. Dropout is the technology that is applied to this problem.
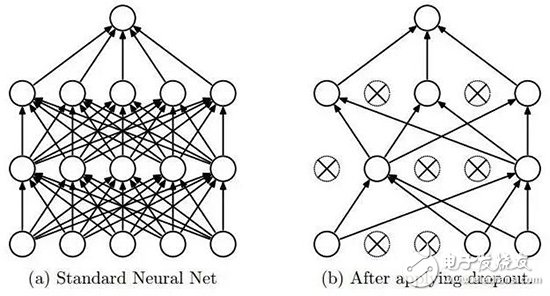
The key idea is to randomly remove the elements of the neural network and the corresponding connections during the training process to prevent overfitting. During training, the dropout will be sampled from an exponential number of different sparse networks. In the testing phase, it is easy to approximate the results by averaging the predictions of these sparse networks with a single untwined network (with smaller weights). This can significantly reduce over-fitting and achieve greater performance gains than other regularization methods. Dropout has been shown to improve neural network performance in supervised learning tasks such as computer vision, speech recognition, text categorization, and computational biology, and achieves top results across multiple benchmark data sets.
5. Maximum poolingMaximum pooling is a sample-based discretization method that aims to downsample input characterization (images, hidden layer output matrices, etc.), reduce dimensions, and allow for the assumption of discarded features contained in sub-regions.
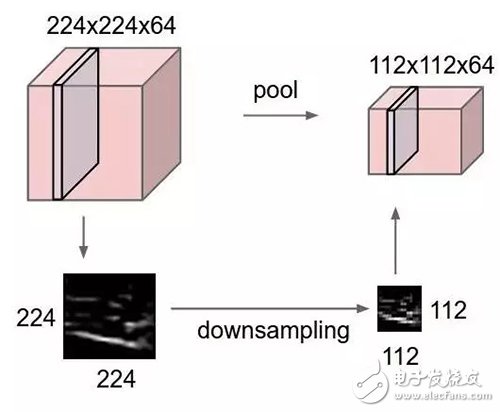
This approach helps to somehow solve the overfitting by providing an abstract form of characterization. Similarly, it also reduces the amount of computation by reducing the number of learning parameters and providing a transformative invariance of basic internal characterization. Maximum pooling extracts features and prevents overfitting by taking maximum values ​​in the initially characterized sub-regions (usually non-overlapping).
6. Batch normalizationNeural networks (including deep networks) often require careful adjustment of weight initialization and learning parameters. Batch normalization makes this process easier.
Weight problem:
Regardless of which weight initialization is performed, such as random or empirically, these weight values ​​differ greatly from the learning weights. Considering a small batch in the initial epoch, there may be many outliers in the required feature activation.
The deep neural network itself is morbid, that is, small changes in the initial layer will lead to huge changes in the next layer.
In the backpropagation process, these phenomena cause the gradient to deviate, meaning that the gradient needs to compensate for the outliers before learning the weights to generate the required output, requiring additional epoch to converge.

Batch normalization systematically gradients to avoid deviations from outliers, leading directly to common targets (by normalization) in several small batches.
Learning rate problem:
The learning rate is usually kept small, so that the correction of the gradient to the weight is small, because the gradient of the abnormal value activation should not affect the learning activation. With batch normalization, these outlier activations are reduced, allowing the learning process to be accelerated with a larger learning rate.
7. Long and short term memoryNeurons in the Long- and Short-Term Memory (LSTM) network are different from the commonly used neurons in other RNNs and have the following three characteristics:
It has a decision on the input of neurons;
It has the right to decide on the storage of the calculated content in the previous time step;
It has the power to decide when to pass the output to the next time step.
The power of LSTM is that it determines all of the above values ​​based only on the current input. Take a look at the chart below:
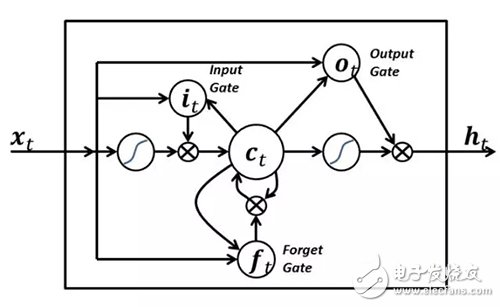
The input signal x(t) of the current time step determines the above three values. The input gate determines the first value, the forget gate determines the second value, and the output gate determines the third value. This is inspired by the way our brain works and can handle sudden scene changes in the input.
8. Skip-gramThe goal of the word embedding model is to learn a high-dimensional dense representation for each lexical item, where the similarity of the embedded vectors represents the semantic or syntactic similarity of the related words. Skip-gram is a model for learning word embedding algorithms.
The main idea behind the skip-gram model (and many other word embedding models) is that if two lexical items have similar contexts, they are similar.
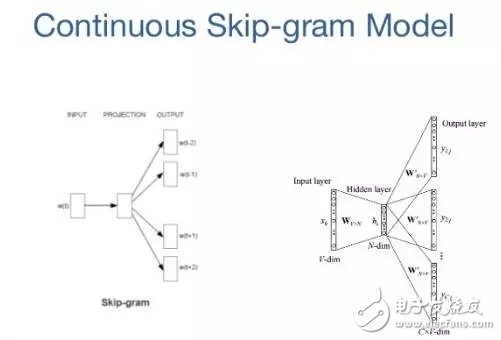
To put it another way, suppose you have a sentence, such as "cats are mammals". If you replace "cats" with "dogs", the sentence still makes sense. So in this example, "dogs" and "cats" have similar contexts (ie, "are mammals").
Based on the above assumptions, we can consider a context window, a window containing k consecutive items. Then we should skip some words to learn the neural network that can get all the items except the skip, and use this neural network to try to predict the skipped items. If two words share a similar context in a large corpus, then these embedded vectors will have very similar vectors.
9. Continuous word bag modelIn natural language processing, we want to learn to represent each word in a document as a vector of values, and to make words that appear in similar contexts have very similar or similar vectors. In the continuous word bag model (CBOW), our goal is to be able to predict the probability of the occurrence of that particular word using the context of a particular word.

We can do this by extracting a large number of statements in a large corpus. Whenever a model sees a word, we extract the contextual word that appears around that particular word. These extracted context words are then input into a neural network to predict the probability of the central word under the conditions in which the context occurs.
When we have thousands of context words and central words, we have a sample of the data set that trains the neural network. In the training neural network, the finally encoded hidden layer outputs the embedded expression of the specific word. This expression is exactly the same context with similar word vectors, and it is just a good idea to use such a vector to represent the meaning of a word.
10. Migration learningNow let us consider how the image flows through the convolutional neural network, which helps us to migrate the knowledge learned by the general CNN to other image recognition tasks. Suppose we have an image, and we put it into the first convolutional layer to get the output of a combination of pixels, which may be some recognized edges. If we use convolution again, we can get a combination of these edges and lines to get a simple graphical outline. This is repeated convolution and finally a specific pattern or image can be searched hierarchically. Therefore, the last layer combines the previously abstract features to find a very specific pattern. If our convolutional network is trained on ImageNet, then the last layer will combine the previous abstract features to identify a specific 1000 categories. If we replace the last layer with the category we want to identify, it can be trained and identified very efficiently.
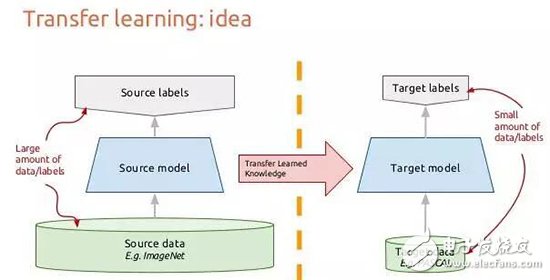
Each layer of the deep convolutional network will construct more and more advanced characterization methods. The last layers are often dedicated to the data we feed into the network, so the features obtained in the early layers are more versatile.
Migration learning is obtained by modifying the CNN model we have trained. We usually cut the last layer and then retrain the newly created new classification layer with the new data. This process can also be interpreted as re-combining with advanced features into new targets that we need to identify. In this way, the training time and data will be greatly reduced. We only need to retrain the last layer to complete the training of the whole model.
Deep learning is very technical, and many techniques do not have much specific explanation or theoretical derivation, but most of the experimental results prove that they are effective. So perhaps understanding these technologies from the ground up is something we need to accomplish later.
Hengstar professional CCTV monitors are designed for professional surveillance systems. The monitors have multi signal input options, and using BNC connectors, which can support long distance signal transmission. Its controller boards have functions of: low EMI, 3D filter and 3D noise reduction and professional Mstar ACE-3 image/color processing and, ensuring the monitors have a perfect image. We have different board solutions for various input needs, and monitors of small size(10.4'') to big size(65'') for option. Our monitors support wall mount and desktop solutions, other mounting solutions are customizable according to customer's requirements. This professional CCTV monitors have been widely applied to control centers, stations, banks, medical diagnose and other site monitoring fields.
cctv monitor,cctv monitor screen,cctv display monitor,surveillance monitor,surveillance monitoring,video surveillance monitors
Shenzhen Hengstar Technology Co., Ltd. , https://www.angeltondal.com