Five Common Clustering Algorithms in Machine Learning
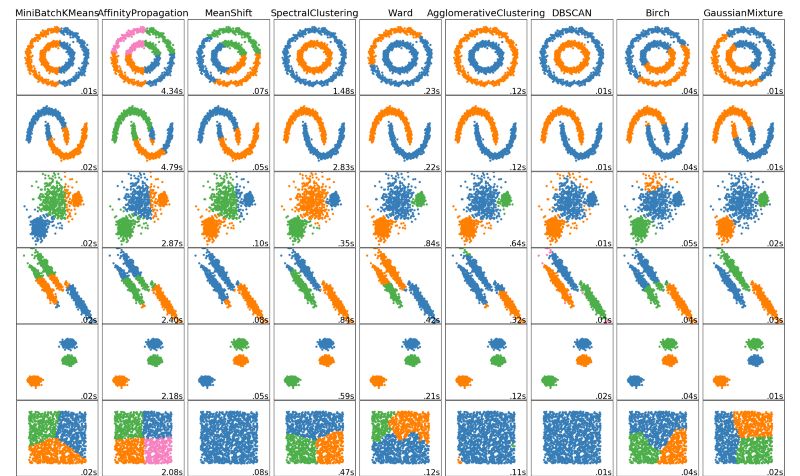
Clustering is an important unsupervised algorithm in machine learning. It can attribute data points to a specific set of combinations. The data points that are theoretically classified as one have the same characteristics, and the data points of different categories have different attributes. Clustering in data science will reveal many perspectives of analysis and understanding from the data, allowing us to further grasp the value of data resources and guide production and life accordingly. The following are five commonly used clustering algorithms.
K-means clustering
This most famous clustering algorithm is mainly based on the mean value between data points and clustering with clustering center. Its main advantage is that it is highly efficient. Since only the distance between the data points and the center of the play is required to be calculated, the computational complexity is only O(n). Its working principle is mainly divided into the following four steps:
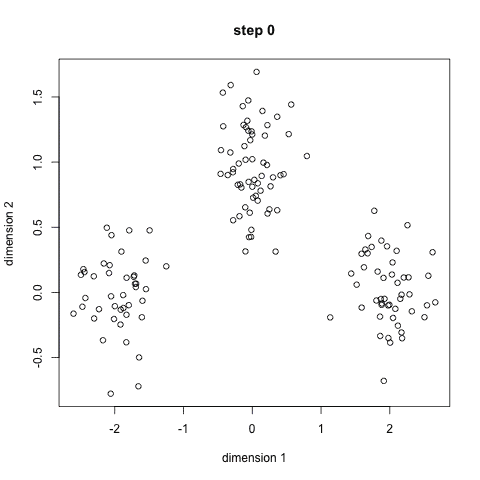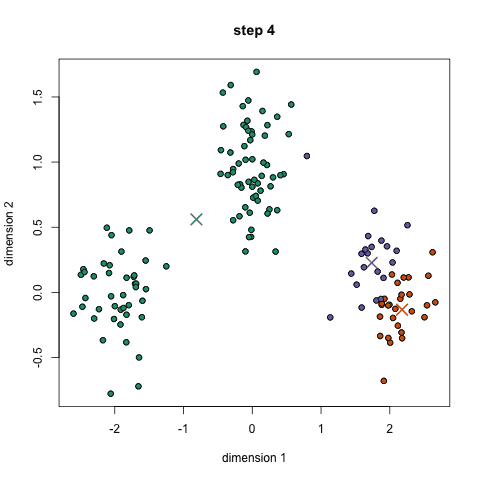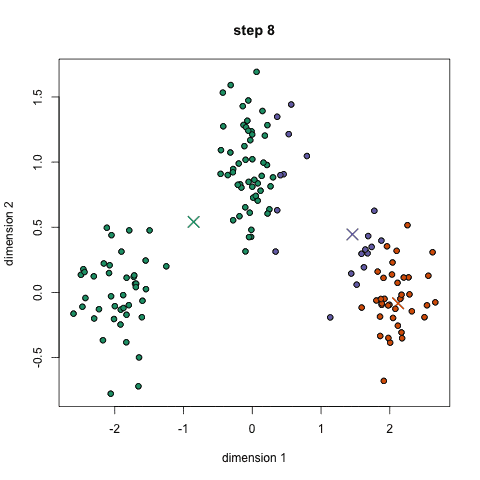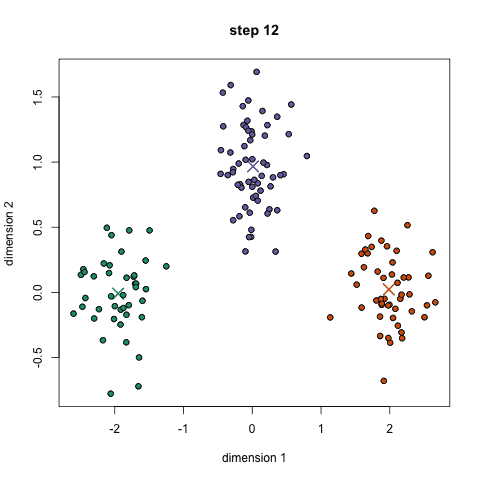
1. First we need to pre-specify the number of clusters and randomly initialize the cluster centers. We can initially observe the data and give a more accurate number of clusters;
2. Each data point is classified into the nearest category by calculating the distance from the cluster center;
3. According to the classification results, use the classified data points to recalculate the cluster centers;
4. Repeat step two three until the cluster center no longer changes. (You can randomly initialize different cluster centers to choose the best result)
This method is very simple in understanding and implementation, but its disadvantages are also very obvious. It depends on the number of clusters initially given; while random initialization may generate different clustering effects, so it lacks repetitiveness and continuity. .
A K-means algorithm similar to the K-means algorithm uses the median to calculate the cluster center in the calculation process, so that the effect of the out-of-plane point on it is greatly reduced; however, the calculation of the median speed vector greatly reduces the calculation of the median vector in each cycle. .
Mean shift algorithm
This is a sliding window-based averaging algorithm that is used to find the area with the highest density in the data points. The goal is to find the center point of each class and update the center point of the sliding window by calculating the mean value of the points within the sliding window. Finally eliminate the influence of adjacent repeats and form a center point, find its corresponding category.
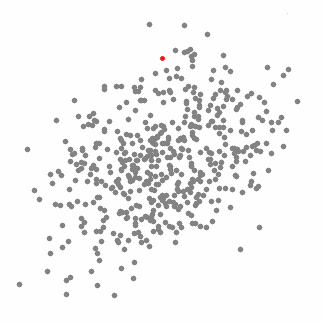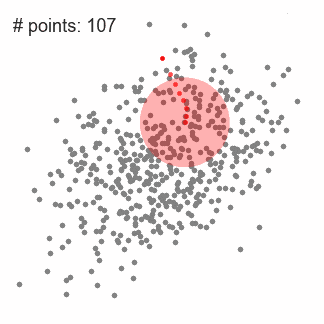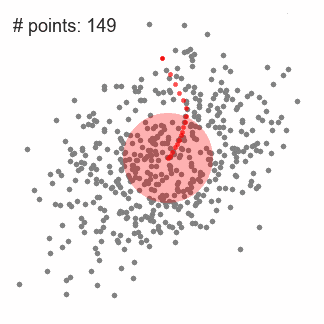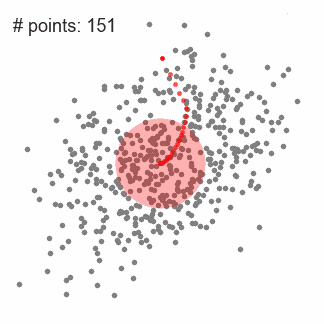
1. First make a circular sliding window with the radius r at the randomly selected point as the radius. The goal is to find the highest density point in the data point and take it as the center;
2. The center of the sliding window after each iteration will move in the direction of higher density;
3. Continuous movement, until the movement of any direction can not increase the number of sliding window midpoint, sliding window convergence at this time;
4. Perform the above steps on multiple sliding windows to cover all points. When a sliding window converges and overlaps, its passing point will be clustered into a class through its sliding window;
Each black dot in the figure below represents the center of a sliding window. They eventually overlap in the center of each category.

The biggest advantage compared to the K-means is that we do not need to specify the number of clusters that are specified, and the center of clustering at the highest density is also consistent with the results of intuition. But its biggest drawback lies in the choice of sliding window size r, which has a great influence on the results.
Density-Based Clustering Algorithm (DBSCAN)
DBSCAN is also a density-based clustering algorithm, but its principle is very different from the mean shift:
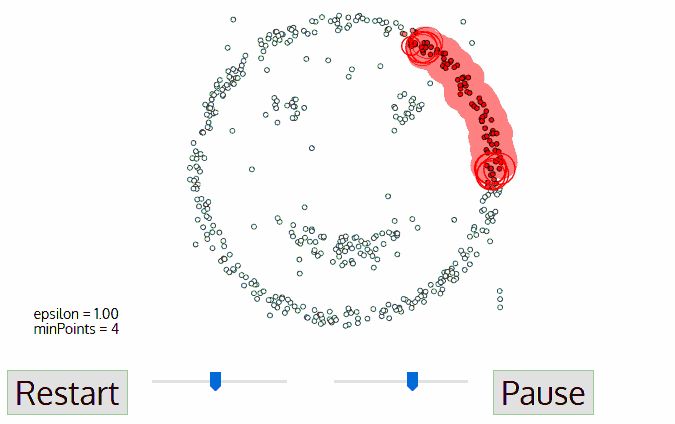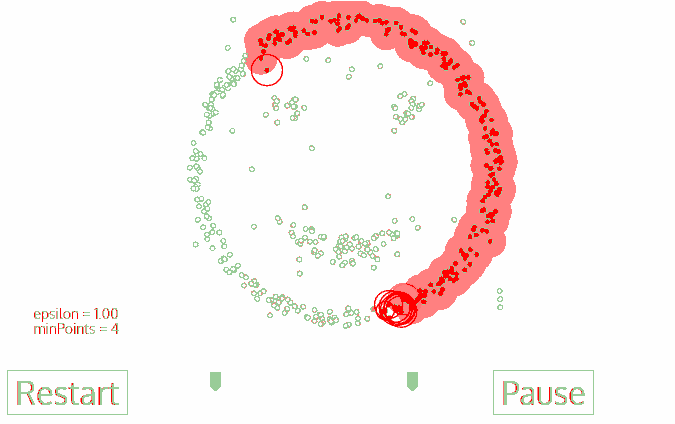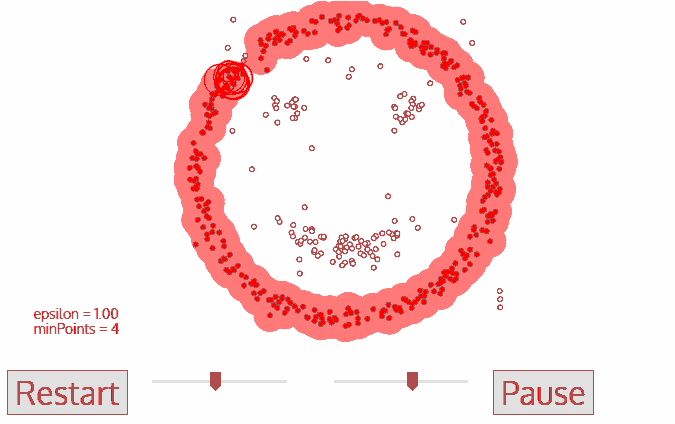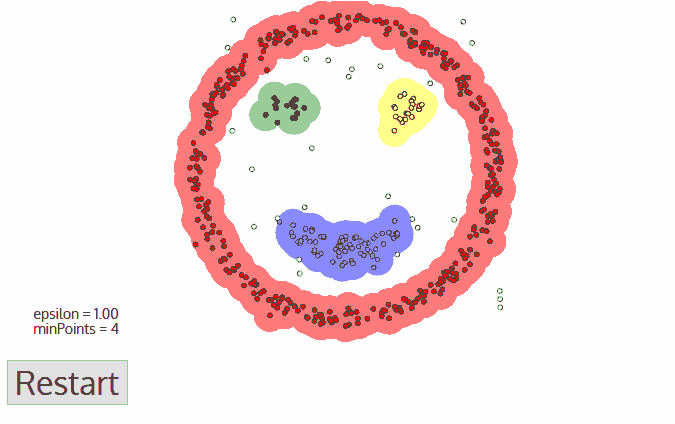
1. Start with any point that has not been traversed first, use the neighborhood distance epsilon to get the surrounding points;
2. If the number of intra-neighborhood points satisfies the threshold, this point becomes the core point and starts a new type of clustering. (marked as noise if not);
3. All the points in its neighborhood also belong to the same class, and all the points in the neighborhood are calculated with the epsilon radius as the second step;
4. Repeat steps two and three until the variable has completed all core point neighborhood points;
5. This type of clustering is completed, and steps 1 to 4 are started with any untraversal point until all data points are processed; eventually each data point has its own attribution class or is noise.
The biggest advantage of this method is that there is no need to define the number of classes. Second, the outliers and noise points can be identified, and any shape data can be clustered.
However, there are also unavoidable shortcomings. When the data density changes drastically, different categories of density threshold points and the radius of the field will change greatly. At the same time, it is not a small challenge to accurately estimate the radius of a field in high-dimensional space.
Maximum Expectation Estimation Using Gaussian Mixture Model
For a more complex distributed K-means, a more outliering clustering result will appear as shown below.

Gaussian mixture model has more flexibility. This is achieved by assuming that the data points conform to the Gaussian mixture model described by the mean and standard deviation. The following figure uses the two-dimensional case as an example to describe how to use the maximum expected optimization algorithm to obtain the distribution parameters:
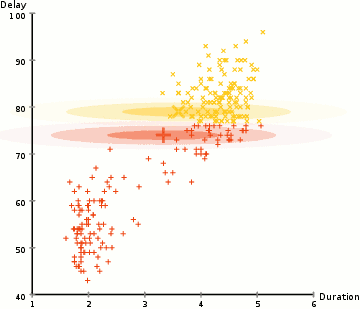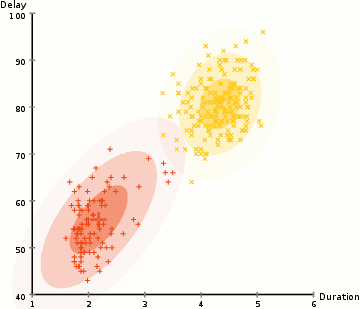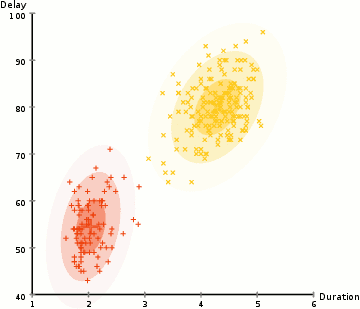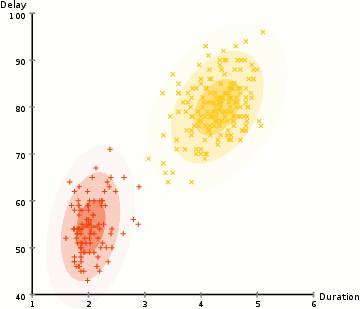
1. First determine the number of clusters and randomly initialize the Gaussian distribution parameters for each cluster;
2. Clustering by calculating the probability that each point belongs to a Gaussian distribution. The closer to the Gaussian center, the more likely it is to belong to this class;
Based on the probabilistic weights of the data points in the previous step, the Gaussian parameters that most likely belong to this cluster are calculated by the method of maximum likelihood estimation;
4. Based on the new Gaussian parameters, re-estimate the probability of ownership of each point, and repeat steps 2 and 3 until the parameters no longer change and converge.
There are two key points when using the Gaussian mixture model. Firstly, the Gaussian mixture model is very flexible and can fit any shape of ellipse. Second, it is a probability-based algorithm. Each point can have a probability of belonging to multiple classes. Mixed attributes.
Agglomerative hierarchical clustering
Hierarchical clustering methods mainly include two methods: top-down and bottom-up. The bottom-up approach, initially seeing each point as a separate category, is followed by a step-by-step cohesion to finally form a large class of independent, all-inclusive data points. This will form a tree structure and form clusters in the process.
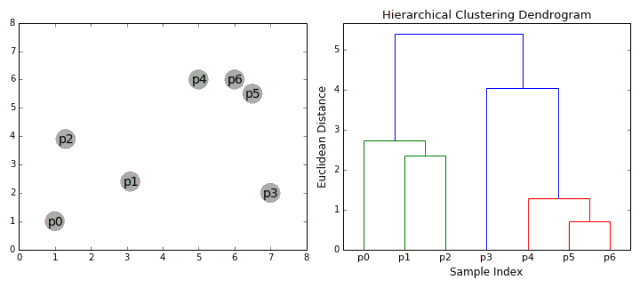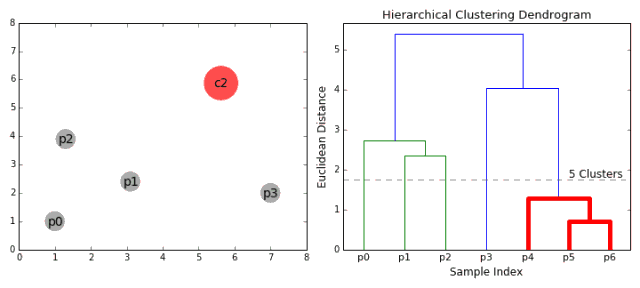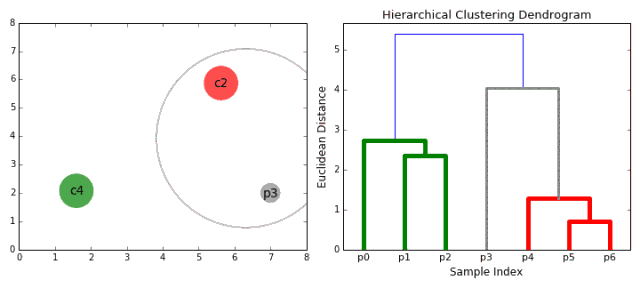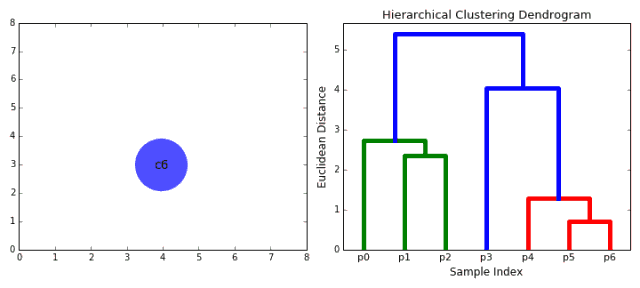
1. First, consider each data point as a category. By calculating the distance between the point and the point, the nearest point is categorized into a sub-category, as the basis for the next clustering;
2. Each iteration clusters two elements into one, and the above-mentioned subclasses are merged into new subclasses. The closest ones are merged together;
3. Repeat step 2 until all categories are merged into one root node. Based on this we can select the number of clusters we need and make selections based on the tree.
Hierarchical clustering does not require the number of classes to be specified in advance, and is insensitive to distance metrics. The best application of this method is to restore the hierarchical structure of the data. But its computational complexity is high to reach O(n^3).
Each clustering algorithm has its own advantages and disadvantages. We need to select the appropriate algorithm for processing according to the calculation requirements and application requirements. With the appearance of deep learning, more neural networks and self-encoders are used to extract high-dimensional features in data for classification, which is a research hotspot.
Finally, if you want to practice your hands, there are many examples of scikit Learn to practice, practice is the best teacher ~~http://scikit-learn.org/stable/modules/clustering.html#clustering
Solid-state Capacitors / Motor Starting Capacitors
Solid - state capacitors are all called: solid - state Aluminum Electrolytic Capacitors.It with the ordinary capacitance (that is, the liquid aluminum electrolytic capacitors) the biggest difference is that use different dielectric material, liquid aluminum capacitor dielectric material as the electrolyte, and solid-state capacitor dielectric material is conductive polymer materials.Solid-state capacitors / Motor starting capacitors
Solid-state capacitors,Motor starting capacitors,Solid-State Capacitors,Solid-State Small Size Capacitors,Solid-State Low Impedance Capacitors,Long Life Solid-State Capacitors
YANGZHOU POSITIONING TECH CO., LTD. , https://www.cndingweitech.com