One of the most popular features of iPhone X is the new unlocking method: FaceID
One of the most popular features of the new iPhone X is the new unlocking method: FaceID. With the creation of a borderless phone, Apple had to develop a new way to unlock the phone simply and quickly. Unlike some competitors who continue to use fingerprint sensors in different locations, Apple decided to revolutionize the way we unlocked our phones, so let's take a look at the phone to unlock it.
With an advanced depth-camera, the iPhone X creates a 3-dimensional map of the user's face. In addition, an infrared camera is used to take a picture of the user's face, which is more robust to changes in the ambient light and color. With deep learning, the smartphone can learn the user's face in great detail, so whenever the phone is picked up by its owner, it will recognize him immediately. Even more surprising is that according to Apple, this method is safer than TouchID, with an error rate of only one in a million.

I am interested in Apple's implementation of FaceID technology, and I want to know how to use deep learning to implement this process and how to optimize each step. In this article, I will show you how to implement a FaceID-like algorithm using Keras. I will explain the various architectural decisions I took and use Kinect to show some final experimental results. It is a very popular RGB depth camera that is very similar to the output of the iPhone X front camera (but with a larger device). So let's start reverse engineering Apple's innovation.
Learn about FaceID
“... The neural network that supports FaceID is not simply performing classification.â€
FaceID setup process
The first step is to carefully analyze how FaceID works on iPhone X. Their white papers can help us understand the basic mechanics of FaceID. In the past, when using TouchID, the user had to initially register their fingerprint by pressing the sensor several times. After about 15-20 different touches, the registration is complete and the TouchID can be used. Similarly, FaceID users also want to register his face. The process is very simple: just look at the phone as usual, then slowly turn your head so you can record your face from different poses. In this way, the process is completed and the phone can be unlocked. This fast registration process can tell us a lot about the potential of this learning algorithm. For example, a neural network that supports FaceID is more than just performing classification.

Apple launches iPhone X and FaceID
Classifying a neural network means learning how to predict whether the face it sees is a user. Therefore, it should mainly use some training data to predict "true" or "false", but unlike many other deep learning use cases, this method does not actually work. First, the network will retrain using new data obtained from the user's face. This requires a lot of time, energy consumption and impractical training data to make negative examples for different faces (which will change if you are migrating learning and fine-tuning on a trained network).
In addition, one reason this method cannot be used is that Apple wants to train more complex offline networks. That is, train in their lab and then send a pre-trained network to the user's phone. Therefore, I believe that FaceID is driven by a similar simese convolutional neural network, which is "offline" trained by Apple to map faces into low-dimensional hidden spaces, using contrast losses. Maximize the distance between different faces. What happens is that you get an architecture that can "one shot learning" (a kind of less accurate classification).

Neural network from digital recognition to face recognition
The twin neural network generally consists of two identical neural networks sharing all the weights. The architecture can learn to calculate the distance between specific types of data. The idea is that you pass data through a twin network (or simply pass data through two different steps over the same network), the network maps it to a low-dimensional feature space, like an n-dimensional array, and then you train the network Map so that data points of different categories are as far as possible, and data points of the same category are as close as possible. The network will learn to extract the most meaningful features from the data and compress them into an array to create a meaningful mapping. To have an intuitive understanding of this, let's imagine using a less-dimensional vector to describe the breed of the dog, so that similar dogs have closer vectors. You might use a number to encode the dog's coat color, another to indicate the size of the dog, another to use for the length of the hair, and so on. In this way, similar dogs will have similar vectors. Twin neural networks can learn to do this for you, similar to an automatic encoder.
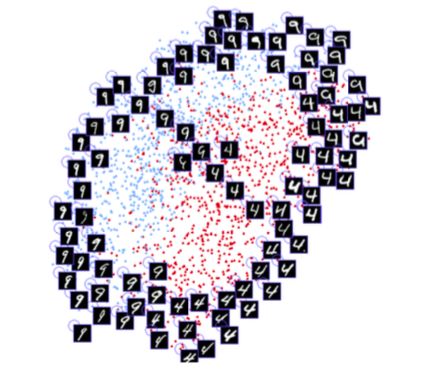
Image courtesy of Hadsell, Chopra and LeCun, "Drawing Dimensions by Learning Invariant Mapping." Note that this architecture is to learn the similarities between numbers and automatically group them into two dimensions. Technically similar to face recognition.
Using this technique, one can use a large number of faces to train this architecture to identify which faces are most similar. If you have good budget and computing power (like Apple), you can use harder examples to make the network more robust to things like twins, against attacks (masks). What are the advantages of using this method? You have a ready-to-use model that recognizes different users without further training. It only needs to take a picture of the user's face in the face mapping space after taking some photos during the initial setup. . . In addition, FaceID can adapt to changes in your aspects: sudden changes (for example, glasses, hats, make-up) and details of changes (facial hair). This is done by adding a vector of reference faces to this map, which is calculated based on your new look.

When your appearance changes, FaceID will adapt
Now let's see how to implement it using Keras.
Implement FaceID in Keras
The first thing we need is data. I found the RGB-D face dataset online. It consists of a series of RGB-D pictures that are oriented in different directions and that make different expressions (in accordance with FaceID).
Implementation: https://github.com/normandipalo/faceID_beta
Colab Notebook: https://colab.research.google.com/drive/1OynWNoWF6POTcRGFG4V7KW_EGIkUmLYI
I created a convolutional network based on the SqueezeNet architecture. The network input couples the RGBD image of the face, so it is 4 channels and outputs the distance between the two embeddings. The network will produce contrast losses when training, minimizing the distance between photos of the same person and maximizing the distance between photos of different people.
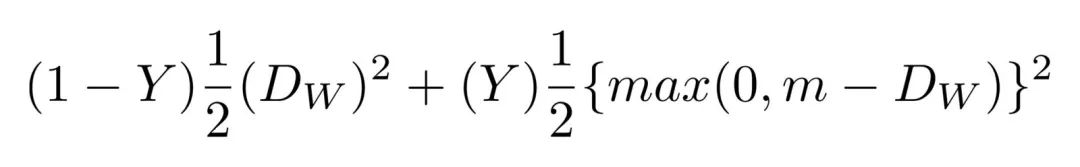
Contrast loss
After some training, the network can map faces into 128-dimensional arrays, so that the same person's pictures are grouped together, and far away from other people's pictures. This means that to unlock your device, the network only needs to calculate the distance between the photos taken during the unlocking process and the photos stored during the registration phase. If the distance is below a certain threshold, the device is unlocked (the smaller the threshold, the more secure the device).
I used the t-SNE algorithm to visualize the 128-dimensional embedded space in 2 dimensions. Each color corresponds to a different person: as you can see, the network has learned to group these pictures correctly. (When the t-SNE algorithm is used, the distance between the clusters is meaningless.) An interesting phenomenon also occurs when using the PCA dimensionality reduction algorithm.
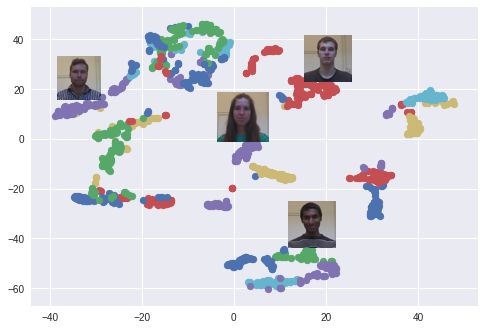
A face cluster in the embedded space created using t-SNE. Each color is a different face (the color is reused).
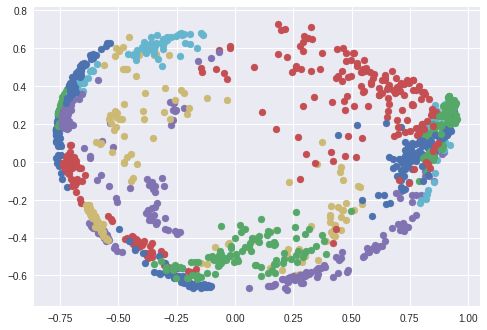
A face cluster in the embedded space created using PCA. Each color is a different face (the color is reused).
experiment
Now we can try to see the operation of this model, it simulates the process of a FaceID: First, register the user's face. Then, the unlock phase, from the user (should be successful), from other people, should not unlock the device. As mentioned earlier, the difference is the distance the network calculates between unlocking the phone and the registered face, and whether it is below a certain threshold.
Let's start with registration: I collected a series of photos of the same person from the dataset and simulated the registration phase. The device begins to calculate the embedding of each pose and stores them locally.

Inspired by the new registration process for FaceID

The registration phase seen by the depth camera
Now let's see what happens if the same user tries to unlock the device. Different poses and facial expressions of the same user achieve a lower distance, about 0.30 points.

The distance that the same user is embedded in the space.
On the other hand, the average distance of RGBD pictures from different people is 1.1.

Distance in different user embedded spaces
Therefore, using a threshold of about 0.4 should be enough to prevent strangers from unlocking your device.
As ar wire automotive Tape Harness Tape,the Car Harness Tape can create a moisture seal and waterproof at wiring harness in automobile industry. And the Automotive Tape will not dry out. Excellent insulation and adhesive properties makes Wire Tape a famours product in our factory.
Compared with Cloth Tape Automotive,our ar wire automotive Tape have the good property of heat resistant, in other words,it is a heat resistant Harness Tape
Automotive Tape,Cloth Tape Automotive,Car wire automotive Tape,Car Harness Tape,heat resistant Harness Tape
CAS Applied Chemistry Materials Co.,Ltd. , https://www.casac1997.com