Linux kernel memory management issues
Foreword
Before the internship, after listening to the sharing of OOM, I was very interested in the memory management of the Linux kernel, but this piece of knowledge is very large, there is no certain accumulation, I dare not write down, I worry about the children, so after a period of accumulation, After some knowledge of kernel memory, write this blog today, record it, and share it.
[OOM - Out of Memory] memory overflow
Memory overflow solution:
1, scale down pictures
2. Use soft references for pictures and recycle () operations in a timely manner.
3, use the loading image frame processing images, such as professional image processing ImageLoader image loading framework, and XUtils BitMapUtils to handle.
This article mainly analyzes the memory layout and allocation of a single process space, and analyzes the memory management of the kernel from a global perspective.
The following mainly introduces Linux memory management from the following aspects:
Memory application and allocation of processes;
OOM after memory exhaustion;
Where are the applications for memory?
System recovery memory;
1, the process of memory application and allocation
There was an article before describing how the hello world program loads memory and how it applies for memory. Here, I explain it again: Similarly, the address space of the process is given first. I think for any developer this map is a must One thing to keep in mind is the timing diagram for operating disk, memory, and cpu cache.
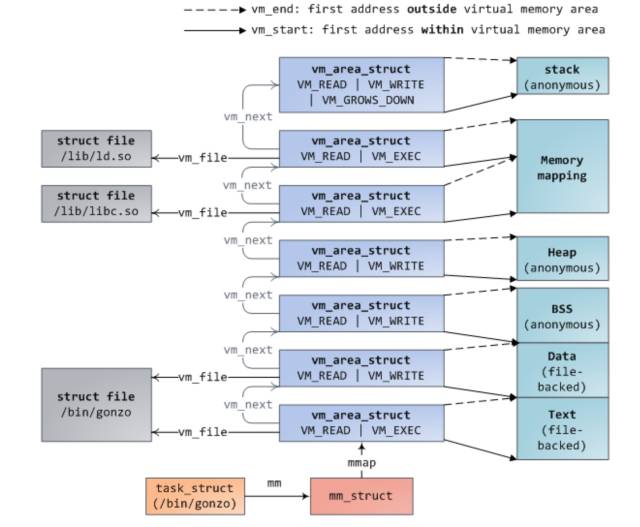
When we start a program on the terminal, the terminal process calls the exec function to load the executable file into memory. At this time, the code segment, data segment, bbs segment, and stack segment are mapped to the memory space through the mmap function. The heap is based on whether there is Apply memory on the heap to decide whether to map.
After exec is executed, the process is not actually started. Instead, the cpu control is passed to the dynamic link library loader, which loads the dynamic link library needed by the process into memory. The execution of the process is only then started. This process can be analyzed by tracing the system functions called by the strace command.

This is my previous blog understanding of the program in the pipe, from this output process, we can see that consistent with my above description.
When the first call to malloc calls for memory, embedded in the kernel through the system call brk, will first make a judgment, whether there is a vma on the heap, if not, then anonymously map a memory to the heap via mmap, and establish a vma structure, hang Go to the red-black tree and linked list on the mm_struct descriptor.
Then return to the user state, through the memory allocator (ptmaloc, tcmalloc, jemalloc) algorithm to manage the allocated memory, return to the user's memory.
If the user mode requests a large memory, it directly calls mmap to allocate memory. At this time, the memory returned to the user mode is still virtual memory, and memory allocation is not performed until the first time the returned memory is accessed.
Actually, virtual memory is returned through brk, but after the memory allocator allocates the cut (cutting must access the memory), all are allocated to physical memory.
When the process frees memory by calling free in the user mode, if the memory is allocated via mmap, munmap is called directly to the system.
Otherwise, the memory is returned to the memory allocator first, and then returned to the system by the memory allocator. This is why when we call free to reclaim memory, we may not report the error when we access the memory again.
Of course, when the entire process exits, the memory used by this process will be returned to the system.
2. After the memory is exhausted, OOM
During the internship, a mysql instance on the tester is often killed by oom. OOM (out of memory) is the self-rescue measure when the system runs out of memory. He chooses a process, kills it, and releases the memory. , Obviously, which process uses the most memory, that is the most likely to be killed, but the fact is this?
Going to work this morning, I just met an OOM and suddenly discovered that OOM once, the world was quiet, haha, redis on the test machine was killed.

OOM key file oom_kill.c, which describes how the system selects the process that should be killed when memory is not enough. There are many selection factors. In addition to the memory used by the process, there is the time the process runs, and the process priority. Level, whether it is a root user process, the number of child processes is related to memory usage and the user control parameter oom_adj.
When the oom is generated, the select_bad_process function will iterate through all processes. Each of the above mentioned factors will get an oom_score score. The highest score is selected as the killing process.
We can set /proc/
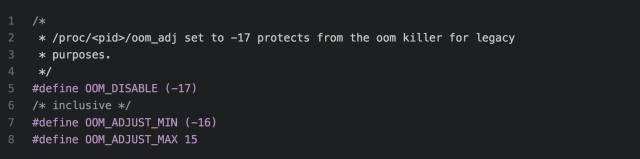
This is the kernel's definition of this oom_adj adjustment value, which can be adjusted to a maximum of 15 and a minimum of -16. If it is -17, the process is like a vip member and will not be killed by the system. Therefore, if If you have a lot of servers running on a machine and you don't want your service to be killed, you can set oom_adj to -17 for your own service.
Of course, when it comes to this, we must mention another parameter /proc/sys/vm/overcommit_memory. The man proc is as follows:

This means that when overcommit_memory is 0, it is a heuristic oom. That is, when the requested virtual memory is not exaggerated larger than physical memory, the system allows the application, but when the virtual memory requested by the process is exaggerated larger than the physical memory, it will Generate OOM.
For example, only 8g of physical memory, then redis virtual memory takes up 24G, physical memory takes up 3g. If bgsave is executed at this time, the child process and the parent process share physical memory, but the virtual memory is its own, that is, the child process will apply for 24g virtual Memory, which is more exaggerated than physical memory, will produce an OOM.
When overcommit_memory is 1, then the overmemory memory application is always allowed, that is, no matter how much your virtual memory request is allowed, but when the system memory is exhausted, oom will be generated at that time, ie the above redis example, in overcommit_memory=1 At this time, no oom will be generated because there is enough physical memory.
When overcommit_memory is 2, you can never exceed a limited amount of memory requests. This limit is swap+RAM* coefficient (/proc/sys/vm/overcmmit_ratio, default 50%, you can adjust it yourself), if so many resources Has been exhausted, then any attempt to apply for memory will return an error, which usually means that no new program can be run at this time
The above is the content of OOM, to understand the principle, and how to set OOM reasonably according to your application.
3, the system application memory is where?
After we understand the address space of a process, will we be curious and where does the physical memory apply? Maybe many people think that physical memory is not it?
I said here where the application memory, because physical memory is divided into cache and general physical memory, you can view through the free command, and physical memory there are three areas of DMA, NORMAL, HIGH, here mainly analyze the cache and ordinary memory .
Through the first part, we know that the address space of a process is almost always the mmap function application, there are two kinds of file mapping and anonymous mapping.
3.1 Shared File Mapping
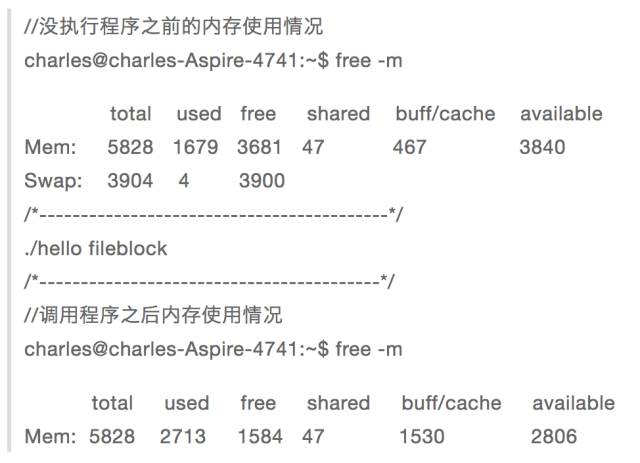
Let's take a look at the code segment and the dynamic link library mapping segment. These two belong to the shared file mapping. That is to say, two processes started by the same executable file share the two segments, and both are mapped to the same. A piece of physical memory, then where is this memory? I wrote a program test as follows:
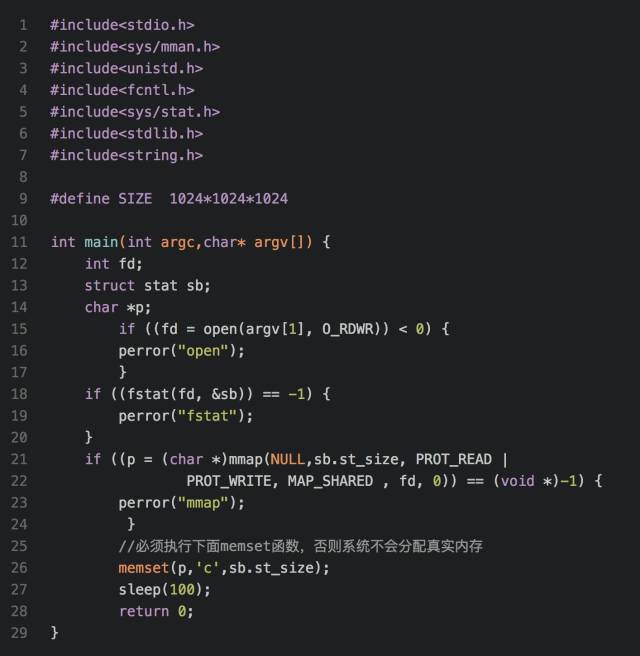
Let's look at the memory usage of the current system:

When I create a new 1G file locally:
Dd if=/dev/zero of=fileblock bs=M count=1024
Then call the above program to perform shared file mapping. At this time, the memory usage is:

We can see that the buff/cache has increased by about 1G, so we can conclude that the code segment and the dynamic link library segment are mapped to the kernel cache, that is, when the shared file mapping is performed, the file is read first. Cache, and then mapped to the user process space.
3.2 Private File Mapping Section
For the data segment in the process space, it must be a private file mapping, because if it is a shared file mapping, then two processes started by the same executable file, any process to modify the data segment, will affect the other process, I Rewrite the above test program as anonymous file mapping:
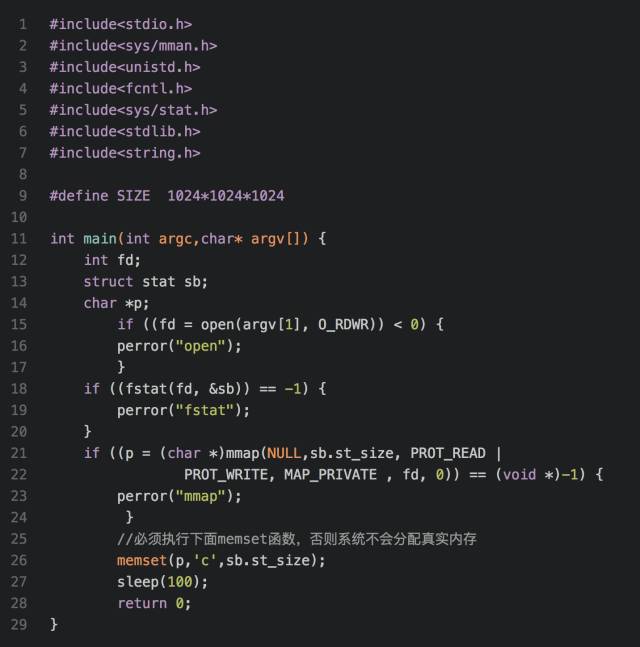
Execution of the program execution, you need to release the previous cache, otherwise it will affect the results
Echo 1 >> /proc/sys/vm/drop_caches
Then execute the program to see the memory usage:
From the comparison before and after use, it can be found that used and buff/cache are increased by 1G, indicating that when performing private file mapping, the file is first mapped to the cache, and if a file is modified on this file, it will be Allocating a piece of memory from other memory first copies the file data to the newly allocated memory, and then modifies it on the newly allocated memory, which is copy-on-write.
This is also very easy to understand, because if the same executable opens more than one instance, the kernel first maps the executable data segment to the cache, and then each instance will allocate a memory storage if there is a modified data segment. Data segment, after all, data segment is also a private process.
Through the above analysis, it can be concluded that if it is a file mapping, the files are mapped to the cache, and then different operations are performed according to the sharing or the private.
3.3 Private Anonymous Mapping
Such as bbs section, heap, and stack are all anonymous maps, because there is no corresponding section in the executable file, and it must be a private map. Otherwise, if the current process forks out a child process, then the parent and child processes will share these sections. Both will affect each other. This is unreasonable.
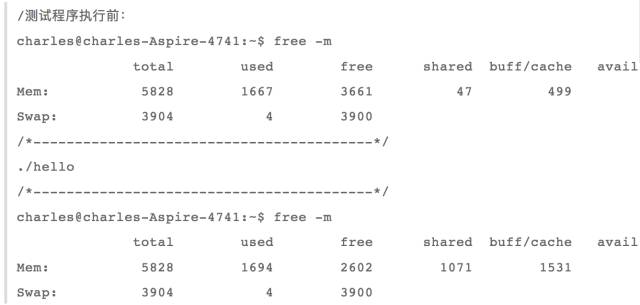
Ok, now I changed the above test program to private anonymous mapping

Then look at the use of memory

We can see that only used has increased 1G, and buff/cache has not grown; this means that when an anonymous private mapping is performed, it does not occupy the cache. In fact, this is justified because only the current process is using this block. Memory, there is no need to take up valuable cache.
3.4 Sharing Anonymous Mappings
When we need to share memory in a parent-child process, we can use mmap to share anonymous mappings. Then where is the memory for sharing anonymous mappings stored? I continue to rewrite the above test program for shared anonymous mappings.

Then look at the use of memory:
From the above results, we can see that only the buff/cache is increased by 1G. That is, when sharing an anonymous mapping, the memory is requested from the cache. The reason is obvious because the parent and child processes share this memory and share the anonymous mapping. Exists in the cache, and then each process is mapped to each other's virtual memory space, so you can operate on the same memory.
4, the system reclaims memory
When the system memory is insufficient, there are two ways to release the memory. One is the manual mode, and the other is the memory recovery triggered by the system. First, look at the manual trigger mode.
4.1 Manually Reclaiming Memory
Manually reclaiming memory, previously demonstrated, ie
Echo 1 >> /proc/sys/vm/drop_caches
We can see an introduction to this in man proc
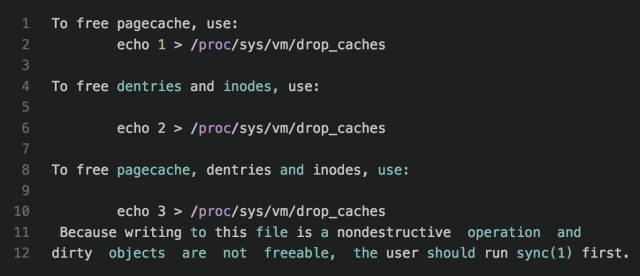
From this introduction we can see that when the drop_caches file is 1, the freed part of pagecache will be released (some caches cannot be released by this), and when drop_caches is 2, the dentist and inodes cache will be released. When drop_caches is 3, this releases both of the above.
The key is the last sentence, which means that if there is dirty data in the pagecache, the operation drop_caches can not be released, you must refresh the dirty data to the disk through the sync command in order to release the pagecache by operating drop_caches.
Ok, before mentioned that some pagecache can not be released through the drop_caches, then in addition to the aforementioned file mapping and shared anonymous mapping, there is something that exists pagecache?
4.2 tmpfs
Let's take a look at tmpfs. tmpfs and procfs, sysfs, and ramfs are memory-based file systems. The difference between tmpfs and ramfs is that ramfs files are based on pure memory, and tmpfs uses swap memory in addition to pure memory. Space, and ramfs may exhaust the memory, and tmpfs can limit the use of memory size, you can use the command df -T -h to view some of the system's file system, some of which are tmpfs, more famous is the directory /dev/shm
Tmpfs file system source files in the kernel source mm/shmem.c, tmpfs implementation is very complicated, before the introduction of the virtual file system, based on the tmpfs file system to create files and other disk-based file system, there will also be inode, super_block, identity, File and other structures, the difference is mainly in reading and writing, because the read and write only involves the file carrier is memory or disk.
The read function shmem_file_read of the tmpfs file mainly finds the address_space address space through the inode structure. It is actually the page cache of the disk file, and then locates the cache page and the offset within the page through the read offset.
At this time, you can directly copy the cached page data to the user space from the pagecache function __copy_to_user. When we want to read the data in the pagecache, we must determine whether it is in the swap, if the memory page is swapped first. In, then read.
Tmpfs file write function shmem_file_write, the process is mainly to determine whether the page to be written in memory, if it is, the user state data is copied directly to the kernel pagecache through the function __copy_from_user to cover the old data, and marked as dirty.
If the data to be written is no longer in memory, then it is judged whether it is in swap, if it is, it is first read out, the old data is overwritten with new data and marked as dirty, and if it is not in memory nor on disk, a new page cache is generated. Store user data.
From the above analysis, we know that tmpfs-based files are also using cache, we can create a file on /dev/shm to detect:

See it, the cache has increased by 1G, verifying the cache memory that tmpfs does use.
In fact, the principle of mmap anonymity mapping is also used tmpfs inside the mm/mmap.c->do_mmap_pgoff function, there is a judgment if the file structure is empty and SHARED mapping, then call shmem_zero_setup (vma) function to create a new file on tmpfs
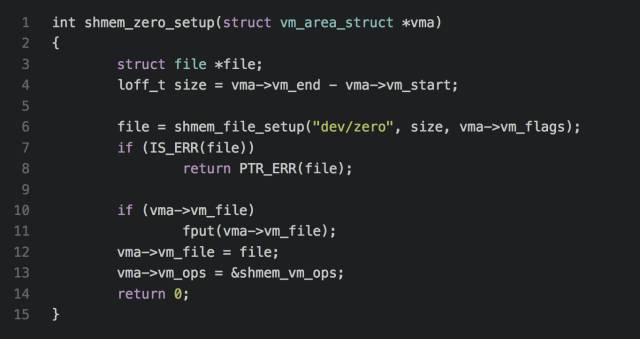
This explains why the shared anonymous mapping memory is initialized to 0, but we know that the memory allocated with mmap is initialized to 0, which means that mmap's private anonymous mapping is also 0, so where is it reflected?
This is not reflected inside the do_mmap_pgoff function, but is a page fault exception and then allocates a special page initialized to zero.
So can the memory pages owned by tmpfs be recycled?

In other words, the pagecache occupied by the tmpfs file cannot be reclaimed, and the reason is obvious. Because there are files referring to these pages, they cannot be recycled.
4.3 Shared Memory
Posix shared memory is in fact the same principle as mmap shared mapping. It uses the tmpfs file system to create a new file, and then maps it to the user state. The last two processes operate on the same physical memory, so whether the System V shared memory is also used Tmpfs file system?
We can trace the following function

This function is to create a new shared memory segment, where function
Shmem_kernel_file_setup
Is to create a file on the tmpfs file system, and then through the memory file to achieve process communication, I do not write the test program, and this is not recyclable, because the shared memory ipc mechanism life cycle is with the kernel, that is to say After you create the shared memory, if the delete is not displayed, the shared memory still exists after the process exits.
Before reading some technical blogs, I mentioned that both the Poxic and System V ipc mechanisms (message queues, semaphores, and shared memory) use the tmpfs file system, which means that the final memory is pagecache, but I'm in the source code. It can be seen that the two shared memories are based on the tmpfs file system, and other semaphores and message queues have yet to be seen (to be followed up).
The implementation of the posix message queue is somewhat similar to pipe's implementation, but also a mqueue file system of its own, and then hangs the message queue attribute mqueue_inode_info on i_private on the inode. In this attribute, kernel 2.6 stores an array with an array of messages. , And to 4.6 with red and black trees to store the message (I downloaded the two versions, specifically when to start using red and black trees, did not dive into).
Then each operation of the two processes is to operate the message array or red-black tree in the mqueue_inode_info to realize the process communication. Similar to this mqueue_inode_info is also the tmpfs file system attribute shmem_inode_info and the file system eventloop serving epoll, and also has a special attribute. Struct eventpoll, this is the private_data etc hanging in the file structure.
Speaking of this, it can be summarized, code segments, data segments, dynamic link libraries (shared file mappings) in the process space, and mmap shared anonymous mappings exist in the cache, but these memory pages are referenced by the process and cannot be released. The life cycle of the tmpfs-based ipc interprocess communication mechanism is with the kernel, and therefore it cannot be released via drop_caches.
Although the above-mentioned cache cannot be released, it is mentioned later that when the memory is insufficient, these memory can be swapped out.
So what drop_caches can release is that when a file is read from a disk and the cache page is mapped to a memory by a process, the process exits. At this time, if the cached page of the mapping file is not referenced, it can be released. .
4.4 Automatic Memory Release Mode
When the system memory is not enough, the operating system has a set of self-organizing memory, and as far as possible to release the memory mechanism, if this mechanism can not release enough memory, then only OOM.
Earlier when referring to OOM, I said redis because OOM was killed, as follows:

In the second half of the second sentence,
Total-vm:186660kB, anon-rss:9388kB, file-rss:4kB
A process memory usage is described with three attributes: all virtual memory, resident memory anonymous mapping pages, and resident memory file mapping pages.
In fact, from the above analysis, we can also know that a process is actually a file mapping and an anonymous mapping:
File mapping: code segment, data segment, dynamic link library shared memory segment and file mapping segment of user program;
Anonymous mapping: bbs section, heap, and memory allocated by malloc using mmap, and mmap shared memory segment;
In fact, kernel recovery memory is based on file mapping and anonymous mapping. The definition in mmzone.h is as follows:
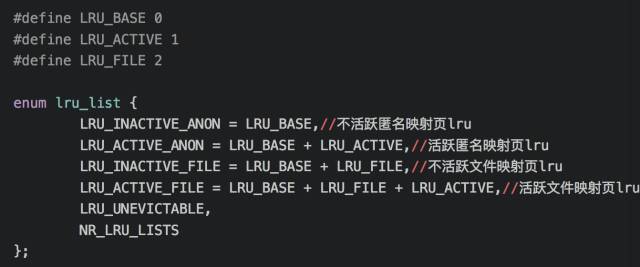
LRU_UNEVICTABLE is not a eviction page lru, my understanding is that when calling mlock to lock the memory, the system is not allowed to swap out the page list.
Simply put, the principle of automatic recovery of memory under the linux kernel, the kernel has a kswapd will periodically check the memory usage, if found free memory is set in the pages_low, then kswapd will lru_list the first four lru queue scan, look in the active list is not Active pages and add inactive links.
Then it traverses the inactive list, and collects and releases 32 pages one by one. It knows that the number of free pages reaches pages_high. For different pages, the collection method is different.
Of course, when the memory level is lower than a certain limit threshold, memory recovery will be directly issued. The principle is the same as that of kswapd, but this time the recovery is more intense and more memory needs to be recovered.
File page:
If it is a dirty page, write back directly to the disk and reclaim the memory.
If it is not a dirty page, then directly release the recovery, because if it is io read the cache, directly release, the next time the page fault, read directly to the disk, if it is a file mapping page, directly released, the next time At the time of access, two page fault exceptions were also generated, one at a time reading the contents of the file into the disk, and the other time associated with the process virtual memory.
Anonymous page: Because the anonymous page does not write back, if it is released, then the data is not found, so the anonymous page recovery is to take swap out to the disk, and make a mark in the page table entry, the next page fault Swap in from the disk into memory.
Swap swapping in and swapping out is actually taking up system IO. If the system memory needs suddenly increase rapidly, then the CPU will be occupied by io and the system will be stuck. As a result, the system cannot provide external services. Therefore, the system provides a parameter for setting. When performing memory reclamation, execute the recycle cache and swap anonymous pages. This parameter is:

This means that the higher the value is, the more likely it is to use swap to reclaim memory. The maximum value is 100. If it is set to 0, the memory is freed as much as possible using a reclaim cache.
5, summary
This article mainly writes about linux memory management related things:
The first is to review the process address space;
Secondly, when the process consumes a large amount of memory and results in insufficient memory, we can have two methods: the first is to manually reclaim the cache, and the second is to use the system background thread swapd to perform memory reclamation.
Finally, when the requested memory is larger than the remaining memory of the system, only OOM is generated, the process is killed, and the memory is released. From this process, it can be seen how hard the system is to make up enough memory.
Curing Screen Protector,Hydrogel Phone Cutting Machine,Protective Film Cutter Machine,Screen Protcter Custting Machine
Shenzhen TUOLI Electronic Technology Co., Ltd. , https://www.hydrogelprotectors.com