How to use Python technology to evaluate Apple's stock price
1. csv data reading
2. Use common functions to obtain statistics such as mean, median, variance, standard deviation, etc.
3. Use common functions to analyze common indicators such as the weighted average of prices, rate of return, annualized volatility, etc. 4. Process the date in the data
We will finally introduce some very useful and commonly used functions in the NumPy library.
You know, NumPy has a lot of commonly used mathematical and statistical analysis functions. If we disperse them one by one, it will be very boring first, and secondly, it will not be remembered. It is like returning to a drowsy classroom. Today We use a background example to connect these scattered knowledge points.
By analyzing Apple’s stock price, we will talk about the commonly used functions of NumPy.
We place the data file AAPL.csv in the same level directory of our python file, and use the excel file to open it to see what it looks like:
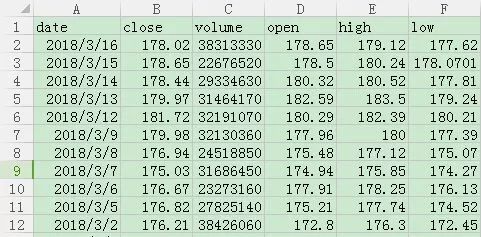
The sequence is the date, closing price, trading volume, opening price, highest price and lowest price. In the CSV file, each column of data is separated by ",". In order to highlight the key points and simplify the procedure, we remove the first line, just Like below
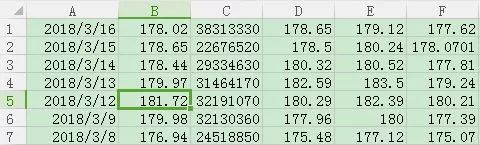
First, we read the two columns of "closing price" and "volume", namely column 1 and column 2 (csv also starts from column 0)
import numpy as np
c , v = np . loadtxt ( 'AAPL.csv' , delimiter = ',' , usecols = ( 1 , 2 ), unpack = True )
print ( c )
print ( v )
[178.02 178.65 178.44 179.97 181.72 179.98 176.94 175.03 176.67 Â 176.82 176.21 175. Â Â 178.12 178.39 178.97 175.5 Â 172.5 Â 171.07 Â 171.85 172.43 172.99 167.37 164.34 162.71 156.41 155.15 159.54 Â 163.03 156.49 160.5 Â 167.78 167.43 166.97 167.96 171.51 171.11 Â 174.22 177.04 177. Â Â 178.46 179.26 179.1 Â 176.19 177.09 175.28 Â 174.29 174.33 174.35 175. Â Â 173.03 172.23 172.26 169.23 171.08 Â 170.6 Â 170.57 175.01 175.01 174.35 174.54 176.42 ]
[ 38313330. 22676520. 29334630. 31464170. 32191070. 32130360. Â 24518850. 31686450. 23273160. 27825140. 38426060. 48706170. Â 37568080. 38885510. 37353670. 33772050. 30953760. 37378070. Â 33690660. 40113790. 50908540. 40382890. 32483310. 60774900. Â 70583530. 54145930. 51467440. 68171940. 72215320. 85957050. Â 44453230. 32234520. 45635470. 50565420. 39075250. 41438280. Â 51368540. 32395870. 27052000. 31306390. 31087330. 34260230. Â 29512410. 25302200. 18653380. 23751690. 21532200. 20523870. Â 23589930. 22342650. 29461040. 25400540. 25938760. 16412270. Â 21477380. 33113340. 16339690. 20848660. 23451420. 27393660. Â 29385650. ]
In this way, we have completed the first task, read the data stored in the csv data file into our two ndarray arrays c and v.
Next, let's try our best to perform the simplest data processing on the closing price and find its average value.
The first one, very simple, is the arithmetic mean we most often see
import numpy as np
c , v = np . loadtxt ( 'AAPL.csv' , delimiter = ',' , usecols = ( 1 , 2 ), unpack = True )
mean_c = np . mean ( c ) print ( mean_c )
172.614918033
The second is the weighted average, we use the volume to weight the average price
That is, the value of the volume is used as the weight. The higher the volume of a certain price, the greater the weight of that price.
import numpy as np
c , v = np . loadtxt ( 'AAPL.csv' , delimiter = ',' , usecols = ( 1 , 2 ), unpack = True )
vwap = np . average ( c , weights = v )
print ( vwap )
170.950010035
Let’s talk about the range of values, find the maximum and minimum values
We look for the maximum and minimum closing price, and the difference between the maximum and minimum
import numpy as np
c = np . loadtxt ( 'AAPL.csv' , delimiter = ',' , usecols = ( 1 ,), unpack = True )
print ( np . max ( c ))
print ( np . min ( c ))
print ( np . ptp ( c ))
181.72
155.15
26.57
Next we carry out a simple statistical analysis
Let's find the median of the closing price first
import numpy as np
c = np . loadtxt ( 'AAPL.csv' , delimiter = ',' , usecols = ( 1 ,), unpack = True )
print ( np . max ( c ))
print ( np . min ( c ))
print ( np . median ( c ))
181.72
155.15
174.35
Find the variance
Another statistic we care about is variance, which can reflect the degree of variable changes. In our example, variance can also tell us the magnitude of investment risk. Those stocks whose stock prices fluctuate too drastically will surely cause trouble for their holders
import numpy as np
c = np . loadtxt ( 'AAPL.csv' , delimiter = ',' , usecols = ( 1 ,), unpack = True )
print ( np . var ( c ))
37.5985528621
Let’s review the definition of difference below. Variance refers to the mean of the sum of squared deviations of each data and the arithmetic mean of all data.
import numpy as np
c = np . loadtxt ( 'AAPL.csv' , delimiter = ',' , usecols = ( 1 ,), unpack = True )
print ( np . mean (( c - c . mean ())** 2 ))
37.5985528621
Compare it up and down and see, the result is exactly the same.
Now let's look at the daily rate of return . This calculation formula is very simple: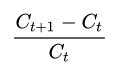
In the diff function, the Nth item of the array is subtracted from the N-1 item to obtain a one-dimensional array of n-1 items. In this example, we noticed that the closer the date in the array is to the closing price, the smaller the array index, so we have to take an opposite number. To sum up the code:
import numpy as np
c = np . loadtxt ( 'AAPL.csv' , delimiter = ',' , usecols = ( 1 ,), unpack = True )
returns = - np diff (c) / c. [1:]
print ( returns )
[- 0.00352645 0.00117687 - 0.00850142 - 0.0096302 Â 0.00966774 0.01718097 Â 0.01091242 - 0.00928284 - 0.00084832 0.00346178 0.00691429 - 0.01751628 - 0.00151354 - 0.00324077 0.01977208 0.0173913 Â 0.00835915 - 0.00453884 - 0.00336368 - 0.00323718 0.0335783 Â 0.01843739 0.01001782 0.04027875 Â 0.00812117 - 0.02751661 - 0.0214071 Â 0.04179181 - 0.02498442 - 0.04339015 Â 0.00209043 0.00275499 - 0.00589426 - 0.0206985 Â 0.00233768 - 0.01785099 - 0.0159286 Â 0.00022599 - 0.00818111 - 0.00446279 0.00089336 0.01651626 - 0.00508216 0.01032634 0.00568019 - 0.00022945 - 0.00011471 - 0.00371429 Â 0.01138531 0.00464495 - 0.00017416 0.01790463 - 0.01081365 0.0028136 Â 0.00017588 - 0.02536998 - 0. Â Â Â Â Â 0.00378549 - 0.00108858 - 0.01065639]
Then, by observing the standard deviation of the daily return, you can see how much the return is fluctuating :
import numpy as np
c = np . loadtxt ( 'AAPL.csv' , delimiter = ',' , usecols = ( 1 ,), unpack = True )
returns = - np diff (c) / c. [1:]
print ( np . std ( returns ))
0.0150780328454
If we want to see which days the return rate is positive, it’s very simple, remember the where statement, let’s use it
import numpy as np
c = np . loadtxt ( 'AAPL.csv' , delimiter = ',' , usecols = ( 1 ,), unpack = True )
returns = - np diff (c) / c. [1:]
print ( np . where ( returns > 0 ))
( array ([ 1 , 4 , 5 , 6 , 9 , 10 , 14 , 15 , 16 , 20 , 21 , 22 , 23 , 24 , 27 , 30 , 31 , 34 , 37 , 40 , 41 , 43 , 44 , 48 , 49 , 51 , 53 , 54 , 57 ], dtype = int64 ),)
Professionally, we can use an indicator called "volatility" to measure price changes . The logarithmic rate of return is needed to calculate the historical volatility. The logarithmic rate of return is very simple, that is 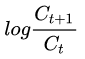
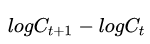
Let's briefly look at the following code
import numpy as np
c = np . loadtxt ( 'AAPL.csv' , delimiter = ',' , usecols = ( 1 ,), unpack = True )
logreturns = -. np diff (. np log (c))
volatility = np . std ( logreturns ) / np . mean ( logreturns )
annual_volatility = volatility / np . sqrt ( 1. / 252. )
print ( volatility )
print ( annual_volatility )
100.096757388
1588.98676256
Here we emphasize one more point: the division calculation is applied in the sqrt method, and floating-point numbers must be used for calculations here. The monthly volatility is the same as using 1./12.
We can often find that in the process of data analysis, the processing and analysis of dates is also a very important content.
Let’s try to use the old method to read out the date data from the csv file.
import numpy as np
dates , c = np . loadtxt ( 'AAPL.csv' , delimiter = ',' , usecols = ( 0 , 1 ), unpack = True )
Traceback ( most recent call last ):
File "E:/12homework/12homework.py" , line 2 , in
dates , c = np . loadtxt ( 'AAPL.csv' , delimiter = ',' , usecols = ( 0 , 1 ), unpack = True )
File "C:\Python34\lib\site-packagesumpy\libpyio.py" , line 930 , in loadtxt
items = [ conv ( val ) for ( conv , val ) in zip ( converters , vals )]
File "C:\Python34\lib\site-packagesumpy\libpyio.py" , line 930 , in
items = [ conv ( val ) for ( conv , val ) in zip ( converters , vals )]
File "C:\Python34\lib\site-packagesumpy\libpyio.py" , line 659 , in floatconv
  return float ( x )
ValueError : could not convert string to float : b '2018/3/16'
We found that he reported an error, the error message is that a byte type object cannot be converted to a floating point type object. The reason is because NumPy is oriented to floating-point operations, so we prescribe the right medicine and perform some conversion processing on the date string.
Let’s first assume that the date is a string type (the downloaded network data often encodes the string into bytecode through utf-8. This can be seen in the introduction of character encoding in the first season)
import numpy as np import datetime
strdate = '2017/3/16'
d = datetime . datetime . strptime ( strdate , '%Y/%m/%d' )
print ( type ( d ))
print ( d )
class 'datetime.datetime'>
2017--03--1600: 00: 00
Through the datetime function package in the python standard library, we specify the matching format %Y/%m/%d
Convert the date string to a datetime type object, Y uppercase matches a complete four-digit year, and lowercase y is two digits, for example 17.
The datetime object has a date method, which removes the time part of the datetime object and turns it into a pure date, and then calls weekday to convert it to the day of the week, which starts from Sunday.
import numpy as np import datetime
strdate = '2018/3/16'
d = datetime . datetime . strptime ( strdate , '%Y/%m/%d' )
print ( d . date ())
print ( d . date (). weekday ())
2018--03--164
Finally, let’s go back to this csv file of Apple’s stock price to do a comprehensive analysis to see which day of the week has the highest average closing price and the lowest day of the week:
import numpy as np import datetime
def datestr2num ( bytedate ):
  return datetime . datetime . strptime (
bytedate . decode ( 'utf-8' ), '%Y/%m/%d' ). date (). weekday ()
dates , c = np . loadtxt ( 'AAPL.csv' , delimiter = ',' , usecols = ( 0 , 1 ),
converters ={ 0 : datestr2num }, unpack = True )
averages = np . zeros ( 5 )
for i in range ( 5 ): Â Â
index = np . where ( dates == i ) Â Â
prices = np . take ( c , index ) Â Â
avg = np . mean ( prices ) Â Â
averages [ i ] = avg print ( "Day {} prices: {},avg={}" . format ( i , prices , avg ))
top = np . max ( averages )
top_index = np. argmax (averages)
bot = np . min ( averages )
bot_index = np. argmin (averages)
print ( 'highest:{}, top day is {}' . format ( top , top_index ))
print ( 'lowest:{},bottom day is {}' . format ( bot , bot_index ))
Day 0 prices : [[ 181.72 176.82 178.97 162.71 156.49 167.96 177. Â Â 174.35 176.42 ]], avg = 172.49333333333334
Day 1 prices: [[179.97 176.67 178.39 171.85 164.34 163.03 166.97 177.04 176.19 Â Â 174.33 172.26 170.57 174.54]], avg = 172.78076923076924
Day 2 prices : [[ 178.44 175.03 178.12 171.07 167.37 159.54 167.43 174.22 179.1 Â Â 174.29 172.23 170.6 Â 174.35 ]], avg = 172.44538461538463
Day 3 prices: [[178.65 176.94 175. Â Â 172.5 Â 172.99 155.15 167.78 171.11 179.26 Â Â 175.28 173.03 171.08 175.01 ]], avg = 172.59846153846152
Day 4 prices : [[ 178.02 179.98 176.21 175.5 Â 172.43 156.41 160.5 Â 171.51 178.46 Â Â 177.09 175. Â Â 169.23 175.01 ]], Fiber Optic Accessories
Fiber Optic Accessories,Fiber Optic Cable Connectors,Fiber Optic Adapter,Fiber Cable Connectors
Huizhou Fibercan Industrial Co.Ltd , https://www.fibercannetworks.com