Use LZ77 algorithm to compress data and realize analysis
Introduction to LZ77
Ziv and Lempel published a paper titled "A Universal Algorithm for Sequential Data Compression (A Universal Algorithm for Sequential Data Compression)" in 1977. The algorithm described in the paper was later called the LZ77 algorithm. It is worth mentioning that LZ77 is not strictly an algorithm, but a coding theory. Like Huffman coding, it only defines the principle, but does not define how to implement it. The algorithm based on this theory is called the LZ77 algorithm, or people prefer to be called the LZ77 variant. In fact, there are many such algorithms, such as LZSS, LZB, LZH, etc. So far, almost all the common compression tools we use daily, such as ARJ, PKZip, WinZip, LHArc, RAR, GZip, ACE, ZOO, TurboZip, Compress, JAR... and even many hardware such as compression algorithms built into network equipment, none of them Exceptions can ultimately be attributed to the outstanding contributions of these two Israelis.
LZ77 is a dictionary-based algorithm that encodes long strings (also known as phrases) into short tokens, and replaces phrases in the dictionary with small tokens to achieve the purpose of compression. In other words, it compresses data by replacing long strings of repeated occurrences in the data with small marks. The symbols handled are not necessarily text characters, but can be symbols of any size.
Maintenance of phrase dictionary
Different dictionary-based algorithms use different methods to maintain their dictionary. LZ77 uses a forward buffer and a sliding window.
LZ77 first loads part of the data into the forward buffer. In order to facilitate the understanding of how the forward buffer stores phrases and forms a dictionary, we describe the buffer as a character sequence of S1,..., Sn, and Pb is a phrase set composed of characters. From the character sequence S1,..., Sn, n phrases are formed, defined as follows:
Pb = {(S1),(S1,S2),…,(S1,…,Sn)}
For example, if the forward buffer contains characters (A,B,D), then the phrase in the buffer is {(A),(A,B),(A,B,D)}.
Once the phrase in the data passes the forward buffer, it will move into the sliding window and become part of the dictionary. To understand how a phrase is represented in a sliding window, first, imagine the window as a sequence of characters S1,..., Sm, and Pw is a phrase set consisting of these characters. The process of generating phrase data sets from sequences S1,..., Sm is as follows:
Pw = {P1,P2,…,Pm}, where Pi = {(Si),(Si,Si+1),…,(Si,Si+1,…,Sm)}
For example, if the sliding window contains symbols (A,B,C), the phrases in the window and dictionary are {(A),(A,B),(A,B,C),(B),(B, C),(C)}.
The main idea of ​​the LZ77 algorithm is to constantly look for the longest phrase that can match the phrase in the dictionary in the forward buffer. Taking the forward buffer and sliding window described above as an example, the longest matching phrase is (A, B).
Compress and decompress data
There are two cases of matching between the forward buffer and the sliding window: either a matching phrase is found, or no matching phrase is found. When the longest match is found, it is encoded as a phrase tag.
The phrase tag contains three parts: 1. The offset in the sliding window (from the head to the previous character before the match); 2. The number of symbols in the match; 3. After the match, the value in the forward buffer The first symbol.
When no match is found, the unmatched symbol is encoded as a symbol mark. This symbol mark only contains the symbol itself, there is no compression process. In fact, we will see that the symbol mark is actually one bit more than the symbol, so there will be a slight expansion.
Once the n symbols are encoded and the corresponding marks are generated, the n symbols are removed from one end of the sliding window and replaced with the same number of symbols in the forward buffer. Then, refill the forward buffer. This process makes the sliding window always have the latest phrase. The number of phrases maintained by the sliding window and the forward buffer is determined by their own capacity.
The following figure (1) shows the process of compressing a string with the LZ77 algorithm, where the size of the sliding window is 8 bytes, and the size of the forward buffer is 4 bytes. In practice, the typical size of a sliding window is 4KB (4096 bytes). The forward buffer size is usually less than 100 bytes.
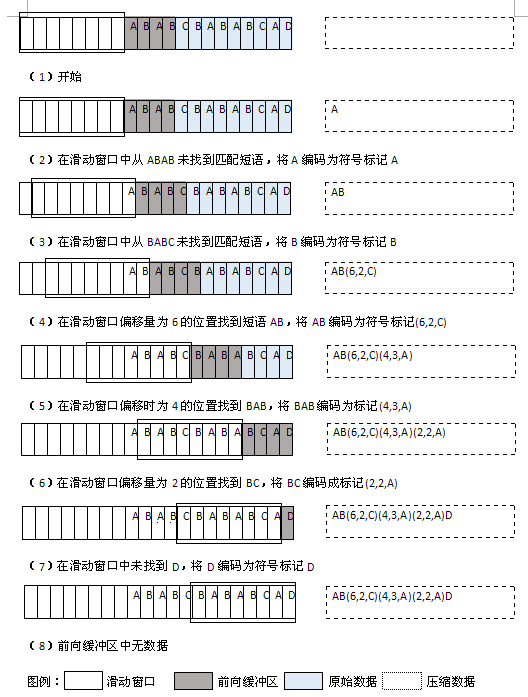
Figure (1): Use LZ77 algorithm to compress the character string ABABCBABABCAD
We decompress the data by decoding the tags and keeping the symbols in the sliding window updated, the process is similar to the compression process. When decoding each mark, the mark is encoded into characters and copied into the sliding window. Whenever a phrase tag is encountered, the corresponding offset is searched in the sliding window, and at the same time a phrase of the specified length found there. Whenever a symbol mark is encountered, a symbol stored in the mark is generated. The following figure (2) shows the process of decompressing the data in figure (1).
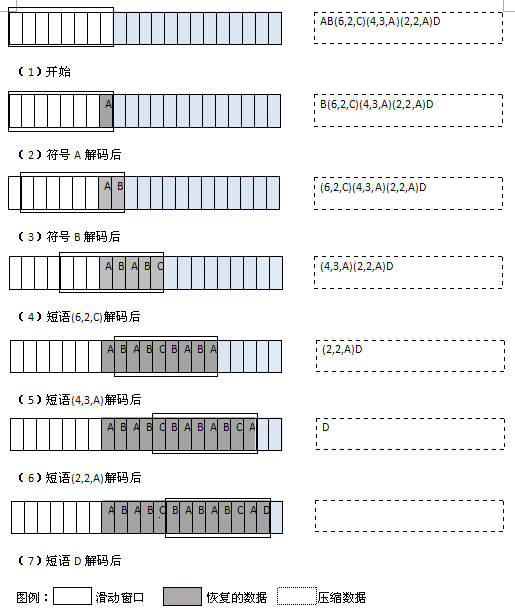
Figure (2): Use the LZ77 algorithm to decompress the compressed string in Figure (1)
LZ77 efficiency
The degree of compression with the LZ77 algorithm depends on many factors, such as the size of the sliding window selected, the size set for the forward buffer, and the entropy of the data itself. Ultimately, the degree of compression depends on the number of phrases that can be matched and the length of the phrase. In most cases, LZ77 has a higher compression ratio than Huffman coding, but its compression process is relatively slow.
Compressing data with the LZ77 algorithm is very time-consuming, and Guowei spends a lot of time looking for matching phrases in the window. However, under normal circumstances, the decompression process of LZ77 is less time-consuming than the decompression process of Huffman coding. The decompression process of LZ77 is very fast because each mark clearly tells us where in the buffer the required symbol can be read. In fact, we ended up reading only the same number of symbols as the original data from the sliding window.
Interface definition of LZ77
lz77_compress
int lz77_compress(const unsigned char *original, unsigned char **compressed, int size);
Return value: If the data compression is successful, return the number of bytes of the compressed data; otherwise, return -1;
Description: Use the LZ77 algorithm to compress the data in the buffer original, which contains size bytes of space. The compressed data is stored in the buffer compressed. lz77_compress needs to call malloc to dynamically allocate storage space for compressed. When this space is no longer used, the caller calls the function free to release the space.
Complexity: O(n), where n is the number of symbols in the original data.
lz77_uncompress
int lz77_uncompress(const unsigned char *compressed, unsigned char **original);
Return value: If the decompression of the data is successful, return the number of bytes of the recovered data; otherwise, return -1;
Description: Use the LZ77 algorithm to decompress the data in the compressed buffer. Assume that the data contained in the buffer was previously compressed by lz77_compress. The restored data is stored in the original buffer. The lz77_uncompress function calls malloc to dynamically allocate storage space for original. When this storage space is no longer used, the caller calls the function free to release the space.
Complexity: O(n) where n is the number of symbols in the original data.
Realization and Analysis of LZ77
The LZ77 algorithm encodes the phrases in the forward buffer into corresponding marks through a sliding window to achieve the purpose of compression. During the decompression process, each token is decoded into a phrase or symbol itself. To do this, the window must be constantly updated, so that at any time during the compression process, the window can be coded according to the rules. In all the examples in this section, one symbol in the original data occupies one byte.
lz77_compress
The lz77_compress operation uses the LZ77 algorithm to compress data. First, it writes the symbols in the data into the compressed data buffer, and initializes the sliding window and the forward buffer at the same time. Subsequently, the forward buffer will be used to load symbols.
Compression occurs in a loop, and the loop continues to iterate until all symbols are processed. Use ipos to save the current byte being processed in the original data, and use opos to save the current bit written to the compressed data buffer. In each iteration of the loop, compare_win is called to determine the longest phrase that matches the forward buffer and the sliding window. The function compare_win returns the length of the longest matching string.
When a matching string is found, compare_win sets offset to the position of the matching string in the sliding window, and sets next to the symbol of the last bit in the forward buffer. In this case, write a phrase tag to the compressed data (Figure 3-a). In the implementation shown in this section, 12 bits are required for the offset phrase mark because the size of the sliding window is 4KB (4096 bytes). At this time, the phrase flag needs 5 bits to indicate the length, because in a 32-byte forward buffer, there will be no matching string exceeding this length. When no matching string is found, compare_win returns and sets next to the unmatched symbol at the beginning of the forward buffer. In this case, write a symbol to the compressed data (Figure 3-b). Regardless of whether a phrase or a symbol is written into the compressed data, the network function htonl needs to be called to convert the string before actually writing the mark to ensure that the mark is in big-endian format. This format is required when actually compressing and decompressing data.

Figure 3: The structure of phrase mark (A) and symbol mark (B) in LZ77
Once the corresponding mark is written into the compressed data buffer, the sliding window and forward buffer are adjusted. To get the data through the sliding window, slide the data into the window from the right and slide out the window from the left. Similarly, the same sliding process is also in the forward buffer. The number of bytes moved is equal to the number of characters encoded in the mark.
The time complexity of lz77_compress is O(n), where n is the number of symbols in the original data. This is because, for each n/c coded mark in the data, where 1/c is a constant factor representing the coding efficiency, compare_win is called once. The function compare_win runs for a fixed period of time because the sizes of the sliding window and the forward buffer are constant. However, these constants are relatively large and will have a greater impact on the overall running time of lz77_compress. Therefore, the time complexity of lz77_compress is O(n), but its actual complexity will be affected by its constant factor. This explains why it is very slow when using lz77 for data compression.
lz77_uncompress
The lz77_uncompress operation decompresses the data compressed by lz77_compress. First, this function reads characters from compressed data and initializes the sliding window and forward buffer.
The decompression process is executed in a loop, and this loop will continue to iteratively execute until all symbols are processed. Use ipos to save the current bit written to the compressed data, and use opos to save the current byte written in the recovery data buffer. In each iteration of the loop, one bit is first read from the compressed data to determine the type of mark to be decoded.
When parsing a tag, if the first bit read is 1, it means that a phrase tag has been encountered. At this time, read each member of it, find the phrase in the sliding window, and then write the phrase into the recovery data buffer. When searching for each phrase, call the network function ntohl to ensure that the byte order of the offset and length in the window matches the operating system. This conversion process is necessary because the offset and length read from the compressed data are in big-endian format. Before the data is copied to the sliding window, the forward buffer is used as a temporary conversion area to save the data. Finally, write the matching symbol of the mark code. If the first bit of the read mark is 0, it means that a symbol mark was encountered. In this case, the matching symbol encoded by the mark is written into the recovery data buffer.
Once the decoded data is written into the recovery data buffer, the sliding window is adjusted. To pass data through a sliding window, slide the data into the window from the right and slide out the window from the left. The number of bytes moved is equal to the number of characters decoded from the mark.
The time complexity of lz77_uncompress is O(n), where n is the number of symbols in the original data.
Problems with failing factory relays, connectors/terminals and fuse contacts are also common when excessive load is placed on them.
Yacenter has experienced QC to check the products in each process, from developing samples to bulk, to make sure the best quality of goods. Timely communication with customers is so important during our cooperation.
If you can't find the exact product you need in the pictures,please don't go away.Just contact me freely or send your sample and drawing to us.We will reply you as soon as possible.
Plate Harness,Pcb Board Harness,Pcb Board Wiring Harness,Pcb Plate Harness
Dongguan YAC Electric Co,. LTD. , https://www.yacentercns.com