Introduction to MySQL data structure and algorithm principle
This article takes MySQL database as the research object and discusses some topics related to database indexes. In particular, it should be noted that MySQL supports many storage engines, and various storage engines support different indexes. Therefore, MySQL database supports multiple index types, such as BTree index, hash index, full-text index and so on. In order to avoid confusion, this article will only focus on the BTree index, because this is the index that usually deals with when using MySQL. As for the hash index and the full-text index, this article will not discuss it.
The main content of the article is divided into three parts.
The first part mainly discusses the mathematical foundation of MySQL database index from the data structure and algorithm theory level.
The second part discusses clustered index, non-clustered index and covering index in combination with the architecture of MyISAM and InnoDB data storage engine in MySQL database.
The third part discusses the high-performance index strategy in MySQL based on the above theoretical foundation.
Data structure and algorithm basis
The nature of the index
MySQL's official definition of index is: Index is a data structure that helps MySQL obtain data efficiently. The essence of the index can be obtained by extracting the main sentence: an index is a data structure.
We know that database query is one of the most important functions of the database. We all hope that the speed of querying data can be as fast as possible, so the designer of the database system will optimize it from the perspective of the query algorithm. The most basic query algorithm is of course linear search. This O(n) algorithm is obviously bad when the amount of data is large. Fortunately, the development of computer science provides many better search algorithms. , Such as binary search (binary search), binary tree search (binary tree search), etc. If you analyze a little bit, you will find that each search algorithm can only be applied to a specific data structure. For example, binary search requires the retrieved data to be ordered, while binary tree search can only be applied to binary search trees, but the data itself The organizational structure cannot completely satisfy various data structures (for example, it is theoretically impossible to organize both columns in order at the same time). Therefore, in addition to data, the database system also maintains a data structure that meets a specific search algorithm. These data Structures reference (point to) data in a certain way, so that advanced search algorithms can be implemented on these data structures. This data structure is the index.
Look at an example:
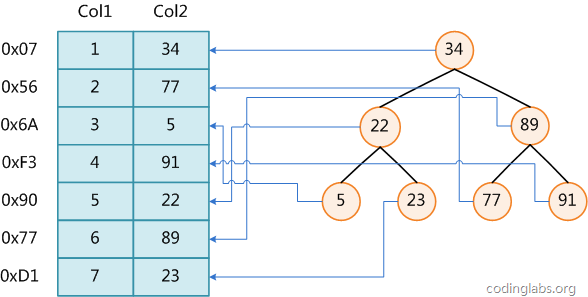
figure 1
Figure 1 shows a possible indexing method. On the left is the data table. There are two columns of seven records. The leftmost is the physical address of the data record (note that logically adjacent records are not necessarily physically adjacent on the disk). In order to speed up the search of Col2, a binary search tree as shown on the right can be maintained. Each node contains an index key value and a pointer to the physical address of the corresponding data record, so that the binary search can be used in O(log2n) Obtain the corresponding data within the complexity.
Although this is a genuine index, the actual database system is hardly implemented using binary search trees or their evolutionary red-black trees. The reasons will be introduced below.
B-Tree and B+Tree
At present, most database systems and file systems use B-Tree or its variant B+Tree as the index structure. In the next section of this article, we will discuss why B-Tree and B+Tree are being used in this way in conjunction with the principle of memory and computer access. Widely used in indexes, this section describes them purely from the perspective of data structure.
B-Tree
To describe B-Tree, first define a data record as a two-tuple [key, data], key is the key value of the record, for different data records, the key is different from each other; data is the data of the data record except the key . Then B-Tree is a data structure that meets the following conditions:
1. d is a positive integer greater than 1, called the degree of B-Tree.
2. h is a positive integer, which is called the height of the B-Tree.
3. Each non-leaf node consists of n-1 keys and n pointers, where d
4. Each leaf node contains at least one key and two pointers, and at most 2d-1 keys and 2d pointers. The pointers of the leaf nodes are all null.
5. All leaf nodes have the same depth, which is equal to the tree height h.
6. The key and the pointer are separated from each other, and the two ends of the node are pointers.
7. The keys in a node are arranged non-decreasingly from left to right.
8. All nodes form a tree structure.
9. Each pointer is either null or points to another node.
10. If a pointer is on the leftmost side of node node and is not null, all keys to the node are less than v(key1), where v(key1) is the value of the first key of node.
11. If a pointer is on the rightmost side of the node node and is not null, then all the keys to the node are greater than v(keym), where v(keym) is the value of the last key of the node.
12. If a pointer to the left and right adjacent keys of node node are keyi and keyi+1 and are not null, then all keys to the node are less than v(keyi+1) and greater than v(keyi).
Figure 2 is a schematic diagram of a B-Tree with d=2.
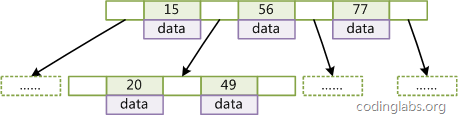
figure 2
Due to the characteristics of B-Tree, the algorithm for retrieving data by key in B-Tree is very intuitive: first, perform a binary search from the root node, if found, return the data of the corresponding node, otherwise search recursively for the node pointed to by the pointer of the corresponding interval , Until a node is found or a null pointer is found, the former finds success, the latter fails. The pseudo code of the search algorithm on B-Tree is as follows:
BTree_Search(node, key)
{
if(node ​​== null) return null;
foreach(node.key)
{
if(node.key[i] == key) return node.data[i];
if(node.key[i]> key) return BTree_Search(point[i]->node);
}
return BTree_Search(point[i+1]->node);
}
data = BTree_Search(root, my_key);
There are a series of interesting properties about B-Tree. For example, a B-Tree of degree d, assuming that its index N keys, then the upper limit of the tree height h is logd((N+1)/2), to retrieve a key, The asymptotic complexity of finding the number of nodes is O(logdN). From this point, it can be seen that B-Tree is a very efficient index data structure.
In addition, since inserting and deleting new data records will destroy the nature of B-Tree, when inserting and deleting, it is necessary to perform operations such as splitting, merging, and transferring the tree to maintain the nature of B-Tree. This article does not intend to discuss B-Tree completely. These contents, because there are already many materials detailing the mathematical properties of B-Tree and the insertion and deletion algorithm, friends who are interested can find the corresponding materials in the reference column at the end of this article to read.
B+Tree
There are many variants of B-Tree, the most common of which is B+Tree. For example, MySQL generally uses B+Tree to implement its index structure.
Compared with B-Tree, B+Tree has the following differences:
1. The upper limit of the pointer of each node is 2d instead of 2d+1.
2. Inner nodes do not store data, only keys; leaf nodes do not store pointers.
Figure 3 is a simple B+Tree schematic.
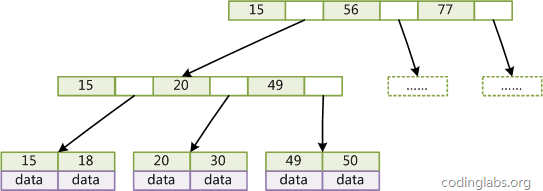
image 3
Since not all nodes have the same domain, leaf nodes and inner nodes in B+Tree generally have different sizes. This is different from B-Tree. Although the number of keys and pointers stored in different nodes in B-Tree may be inconsistent, the domain and upper limit of each node are the same, so in the implementation, B-Tree often applies for each node to be equal The size of the space.
Generally speaking, B+Tree is more suitable for implementing external storage index structure than B-Tree. The specific reasons are related to the principle of external storage and computer access principles, which will be discussed below.
B+Tree with sequential access pointer
Generally, the B+Tree structure used in the database system or file system is optimized on the basis of the classic B+Tree, adding sequential access pointers.
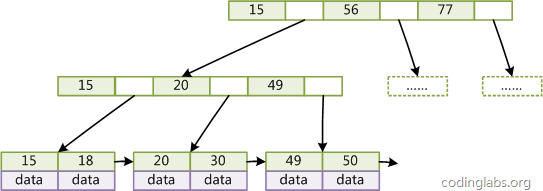
Figure 4
As shown in Figure 4, each leaf node of the B+Tree adds a pointer to the adjacent leaf node to form a B+Tree with sequential access pointers. The purpose of this optimization is to improve the performance of interval access. For example, in Figure 4, if you want to query all data records whose key is from 18 to 49, when you find 18, you only need to traverse the nodes and pointers in order to access them at once. To all data nodes, the efficiency of interval query is greatly mentioned.
This section gives a brief introduction to B-Tree and B+Tree, and the next section introduces why B+Tree is currently the preferred data structure for indexing in database systems based on the principle of memory access.
Why use B-Tree (B+Tree)
As mentioned above, data structures such as red-black trees can also be used to implement indexes, but file systems and database systems generally use B-/+Tree as the index structure. This section will discuss B-/+ with the knowledge of computer composition principles. Tree serves as the theoretical basis of the index.
Main memory access principle
At present, the main memory used by computers is basically random read-write memory (RAM). The structure and access principle of modern RAM are more complicated. This article ignores the specific differences and abstracts a very simple access model to illustrate the working principle of RAM.
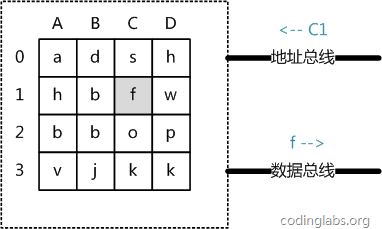
Figure 5
From an abstract perspective, the main memory is a matrix composed of a series of storage units, and each storage unit stores fixed-size data. Each storage unit has a unique address. The addressing rules of modern main memory are more complicated. Here, it is simplified into a two-dimensional address: a storage unit can be uniquely located through a row address and a column address. Figure 5 shows a 4 x 4 main memory model.
The main memory access process is as follows:
When the system needs to read the main memory, it puts the address signal on the address bus and uploads it to the main memory. After the main memory reads the address signal, it analyzes the signal and locates it to the designated storage unit, and then puts the storage unit data on the data bus , For other components to read.
The process of writing main memory is similar. The system puts the unit address and data to be written on the address bus and data bus respectively, and the main memory reads the contents of the two buses and performs corresponding write operations.
It can be seen here that the main memory access time is only linearly related to the number of accesses. Because there is no mechanical operation, the "distance" of the data accessed twice will not have any effect on the time. For example, take A0 first and then take it. The time consumption of A1 is the same as taking A0 first and then taking D3.
Principles of Disk Access
As mentioned above, indexes are generally stored on disk in the form of files, and index retrieval requires disk I/O operations. Unlike main memory, disk I/O has mechanical movement costs, so the time consumption of disk I/O is huge.
Figure 6 is a schematic diagram of the overall structure of the magnetic disk.
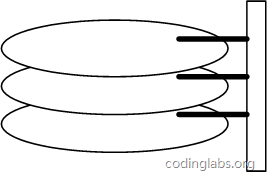
Figure 6
A disk is composed of circular disks of the same size and coaxial. The disks can rotate (each disk must rotate synchronously). There is a head holder on one side of the disk. The head holder fixes a group of heads, and each head is responsible for accessing the contents of a disk. The magnetic head cannot rotate, but it can move along the radius of the disk (actually in the oblique tangential direction). Each head must also be coaxial at the same time, that is, when viewed from directly above, all heads overlap at all times (but At present, there are independent technologies for multiple heads, which are not subject to this limitation).
Figure 7 is a schematic diagram of the disk structure.
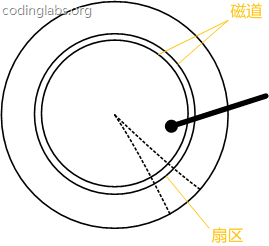
Figure 7
The disc is divided into a series of concentric rings. The center of the circle is the center of the disc. Each concentric ring is called a track. All tracks with the same radius form a cylinder. The track is divided into small segments along the radius line. Each segment is called a sector, and each sector is the smallest storage unit of the disk. For the sake of simplicity, we assume that the disk has only one platter and one head.
When data needs to be read from the disk, the system transmits the data logical address to the disk. The control circuit of the disk translates the logical address into a physical address according to the addressing logic, that is, to determine which track and sector the data to be read is on. In order to read the data in this sector, the magnetic head needs to be placed above this sector. In order to achieve this, the magnetic head needs to move to align with the corresponding track. This process is called seek, and the time consumed is called seek time. The time the target sector rotates under the head is called the rotation time.
The principle of locality and disk read-ahead
Due to the characteristics of the storage medium, the disk access is much slower than the main memory. In addition to the mechanical movement, the access speed of the disk is often a few hundredths of the main memory. Therefore, in order to improve efficiency, minimize the disk I/O. In order to achieve this goal, the disk is often not read strictly on-demand, but read ahead every time. Even if only one byte is needed, the disk will start from this position and read a certain length of data sequentially backwards into the memory. The theoretical basis for this is the famous locality principle in computer science:
When a piece of data is used, the nearby data is usually used immediately.
The data needed during the program is usually concentrated.
Because the disk sequential read efficiency is very high (no seek time is required, only a small rotation time is needed), for a program with locality, pre-reading can improve I/O efficiency.
The length of pre-reading is generally an integral multiple of a page. A page is a logical block of computer management memory. The hardware and operating system often divide the main memory and the disk storage area into continuous blocks of equal size. Each memory block is called a page (in many operating systems, the page size is usually 4k), the main memory and disk exchange data in units of pages. When the data to be read by the program is not in the main memory, a page fault exception will be triggered. At this time, the system will send a disk read signal to the disk, and the disk will find the starting position of the data and read one or several pages continuously. Load into the memory, then return abnormally, the program continues to run.
Performance analysis of B-/+Tree index
Here we can finally analyze the performance of the B-/+Tree index.
As mentioned above, the number of disk I/Os is generally used to evaluate the pros and cons of the index structure. Analyzing from B-Tree first, according to the definition of B-Tree, it can be known that at most h nodes need to be visited for one search. The designer of the database system cleverly used the disk read-ahead principle and set the size of a node equal to one page, so that each node only needs one I/O to be fully loaded. In order to achieve this goal, the following techniques are needed to actually implement B-Tree:
Every time you create a new node, you directly apply for a page space, which ensures that a node is also physically stored in a page. In addition, the computer storage allocation is page-aligned, so that a node only needs one I/O.
A search in B-Tree requires at most h-1 I/O (root node resident memory), and the progressive complexity is O(h)=O(logdN). In general practical applications, the degree d is a very large number, usually more than 100, so h is very small (usually not more than 3).
In summary, the efficiency of using B-Tree as an index structure is very high.
With this structure of red-black tree, h is obviously much deeper. Since logically close nodes (parent and child) may be physically far away and locality cannot be used, the I/O progressive complexity of the red-black tree is also O(h), which is significantly less efficient than B-Tree.
As mentioned above, B+Tree is more suitable for external storage index, the reason is related to the internal node out degree d. It can be seen from the above analysis that the larger d, the better the performance of the index, and the upper limit of the out degree depends on the size of the key and data in the node:
dmax = floor(pagesize / (keysize + datasize + pointsize)) (pagesize – dmax >= pointsize)
or
dmax = floor(pagesize / (keysize + datasize + pointsize)) – 1 (pagesize – dmax
floor means rounding down. Since the data field is removed from the node in the B+Tree, it can have a greater degree of output and better performance.
This chapter discusses data structure and algorithm issues related to indexes from a theoretical perspective. The next chapter will discuss how B+Tree is implemented as an index in MySQL. At the same time, it will combine MyISAM and InnDB storage engines to introduce non-clustered indexes and clustered indexes. Two different index implementation forms.
MySQL index implementation
In MySQL, the index belongs to the concept of the storage engine level. Different storage engines implement indexes in different ways. This article mainly discusses the index implementation methods of the MyISAM and InnoDB storage engines.
MyISAM index implementation
The MyISAM engine uses B+Tree as the index structure, and the data field of the leaf node stores the address of the data record. The following figure is the schematic diagram of MyISAM index:
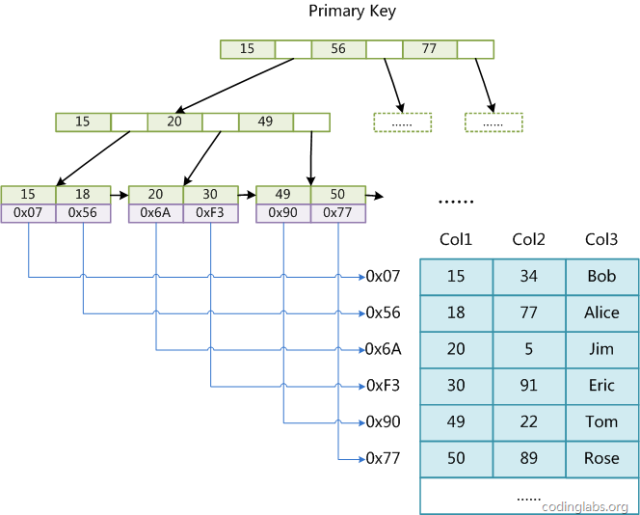
Figure 8
There are three columns in the table. Assuming that we use Col1 as the primary key, Figure 8 shows the primary key of a MyISAM table. It can be seen that the MyISAM index file only saves the address of the data record. In MyISAM, there is no difference in structure between the primary index and the secondary index (Secondary key), but the primary index requires the key to be unique, and the key of the secondary index can be repeated. If we build an auxiliary index on Col2, the structure of this index is shown in the figure below:
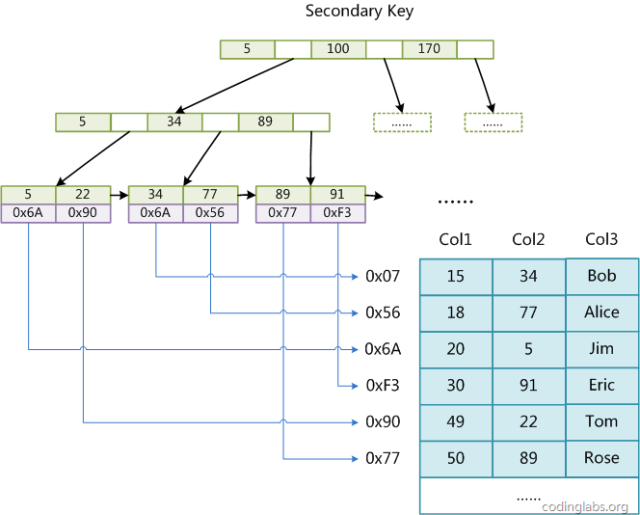
Picture 9
It is also a B+Tree, and the data field saves the address of the data record. Therefore, the index retrieval algorithm in MyISAM is to first search the index according to the B+Tree search algorithm. If the specified Key exists, then take out the value of its data field, and then use the value of the data field as the address to read the corresponding data record.
MyISAM's indexing method is also called "non-clustered", and the reason for this is to distinguish it from InnoDB's clustered index.
InnoDB index implementation
Although InnoDB also uses B+Tree as an index structure, the specific implementation is completely different from MyISAM.
The first major difference is that InnoDB's data files are themselves index files. As we know from the above, the MyISAM index file and the data file are separated, and the index file only saves the address of the data record. In InnoDB, the table data file itself is an index structure organized by B+Tree, and the leaf node data field of this tree saves complete data records. The key of this index is the primary key of the data table, so the InnoDB table data file itself is the primary index.
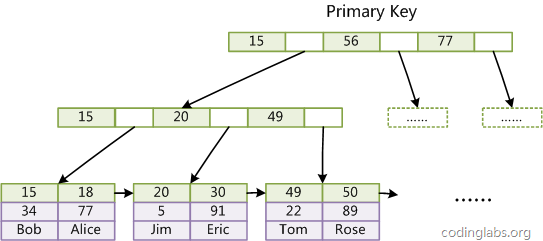
Picture 10
Figure 10 is a schematic diagram of the InnoDB main index (also a data file), you can see that the leaf node contains a complete data record. This kind of index is called a clustered index. Because InnoDB's data file itself needs to be aggregated by the primary key, InnoDB requires the table to have a primary key (MyISAM may not). If it is not explicitly specified, the MySQL system will automatically select a column that can uniquely identify the data record as the primary key. If it does not exist For this kind of column, MySQL automatically generates a hidden field for the InnoDB table as the primary key. The field length is 6 bytes and the type is long integer.
The second difference from MyISAM index is that InnoDB's secondary index data field stores the value of the primary key of the corresponding record instead of the address. In other words, all InnoDB secondary indexes refer to the primary key as the data field. For example, Figure 11 is an auxiliary index defined on Col3:
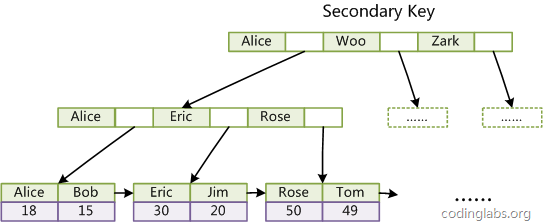
Picture 11
The ASCII code of English characters is used as the comparison criterion here. This implementation of the clustered index makes the search by the primary key very efficient, but the secondary index search needs to retrieve the index twice: first retrieve the secondary index to obtain the primary key, and then use the primary key to retrieve the records from the primary index.
Understanding the index implementation methods of different storage engines is very helpful for the correct use and optimization of indexes. For example, after knowing the index implementation of InnoDB, it is easy to understand why it is not recommended to use too long fields as the primary key, because all secondary indexes refer to the primary key. Index, a long primary index will make the secondary index too large. For another example, using non-monotonic fields as the primary key is not a good idea in InnoDB, because the InnoDB data file itself is a B+Tree, and the non-monotonic primary key will cause the data file to maintain the characteristics of B+Tree when inserting new records. Frequent split adjustments are very inefficient, and using auto-increment fields as primary keys is a good choice.
The next chapter will specifically discuss these optimization strategies related to indexes.
Index usage strategy and optimization
MySQL optimization is mainly divided into structure optimization (Scheme optimization) and query optimization (Query optimization). The high-performance indexing strategies discussed in this chapter mainly belong to the category of structural optimization. The content of this chapter is completely based on the theoretical basis above. In fact, once you understand the mechanism behind the index, then choosing a high-performance strategy becomes pure reasoning, and you can understand the logic behind these strategies.
Sample database
In order to discuss the indexing strategy, a database with a small amount of data is needed as an example. This article uses one of the sample databases provided in the official MySQL documentation: employees. This database has moderate complexity and a large amount of data. The following figure is the ER relationship diagram of this database (quoted from the official MySQL manual):
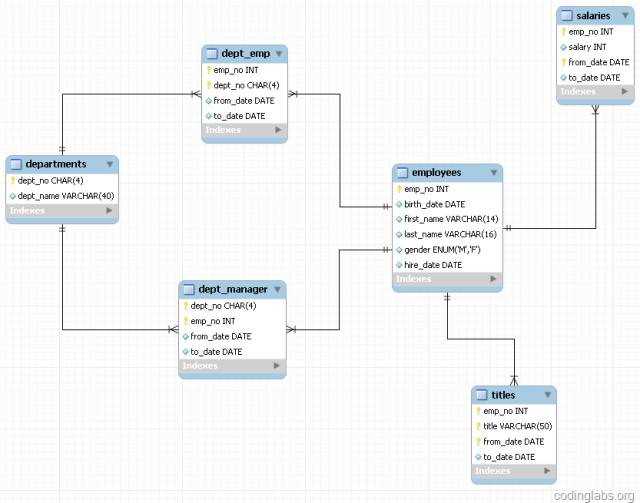
Picture 12
The page on this database in the official MySQL documentation is http://dev.mysql.com/doc/employee/en/employee.html. The database is introduced in detail, and the download address and import method are provided. If you are interested in importing this database to your own MySQL, you can refer to the content in the article.
The principle of the leftmost prefix and related optimization
The first condition for efficient use of indexes is to know what kind of queries will use the index. This problem is related to the "leftmost prefix principle" in B+Tree. The following examples illustrate the leftmost prefix principle.
Let me talk about the concept of joint index first. In the above, we have assumed that the index only refers to a single column. In fact, an index in MySQL can refer to multiple columns in a certain order. This kind of index is called a joint index. Generally, a joint index is an ordered element Group, where each element is a column of the data table, in fact, to strictly define the index requires the use of relational algebra, but here I don’t want to discuss too much topic of relational algebra, because that would seem very boring, so I won’t be strict here. definition. In addition, a single-column index can be regarded as a special case where the number of elements in a joint index is 1.
Take the employees.titles table as an example, let's first check which indexes are on it:
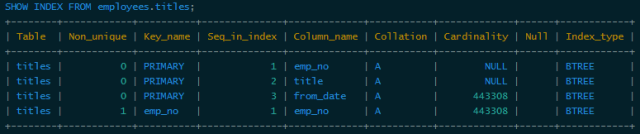
From the results, you can find the main index of the titles table, as well as an auxiliary index. In order to prevent multiple indexes from complicating things (MySQL's SQL optimizer behaves more complicatedly when there are multiple indexes), here we drop the auxiliary index:
ALTER TABLE employees.titles DROP INDEX emp_no;
So you can concentrate on analyzing the behavior of the index PRIMARY.
Case 1: Full column matching.

Obviously, the index can be used when performing exact matching according to all columns in the index (here exact matching refers to "=" or "IN" matching). One thing to note here is that the index is theoretically sensitive to order, but because MySQL's query optimizer will automatically adjust the order of the conditions of the where clause to use a suitable index, for example, we reverse the order of conditions in where:

The effect is the same.
Case 2: The leftmost prefix matches.

When the query condition exactly matches one or several columns on the left side of the index, such as or, it can be used, but only part of it, that is, the leftmost prefix composed of the condition. The above query uses the PRIMARY index from the analysis results, but the key_len is 4, indicating that only the first column prefix of the index is used.
Case 3: The query condition uses the exact match of the column in the index, but one of the conditions in the middle is not provided.

At this time, the index usage is the same as in case two. Because the title is not provided, only the first column of the index is used in the query. Although the later from_date is also in the index, it cannot be connected with the left prefix because the title does not exist, so it needs Scan and filter the results from_date (here, because emp_no is unique, there is no scan). If you want from_date to also use an index instead of where to filter, you can add an auxiliary index, and the above query will use this index. In addition, you can also use an optimization method called "isolation column" to fill in the "pit" between emp_no and from_date.
First of all, let’s look at the different values ​​of title:
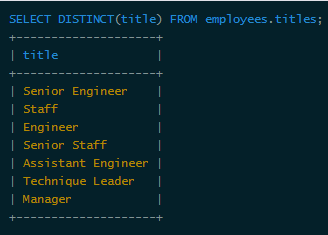
There are only 7 kinds. In this case where there are fewer column values ​​called "pits", you can consider using "IN" to fill this "pit" to form the leftmost prefix:
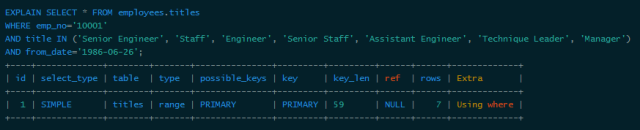
This time key_len is 59, indicating that the index is fully used, but from the type and rows we can see that IN actually executed a range query, here 7 keys are checked. Look at the performance comparison of the two queries:

The performance has improved a bit after "filling the hole". If a lot of data is left after emp_no filtering, the performance advantage of the latter will be more obvious. Of course, if the value of the title is too large, it is not appropriate to fill the hole, and an auxiliary index must be established.
Case 4: The query condition does not specify the first column of the index.

Since it is not the leftmost prefix, the index is obviously not used for queries such as indexes.
Situation five: match the prefix string of a certain column.

The index can be used at this time, but if the wildcard does not only appear at the end, the index cannot be used. (The original text is incorrect. If the wildcard% does not appear at the beginning, the index can be used, but depending on the specific situation, only one of the prefixes may be used)
Situation 6: Scope query.

The range column can use the index (must be the leftmost prefix), but the column after the range column cannot use the index. At the same time, the index is used for at most one range column, so if there are two range columns in the query condition, the index cannot be used all.
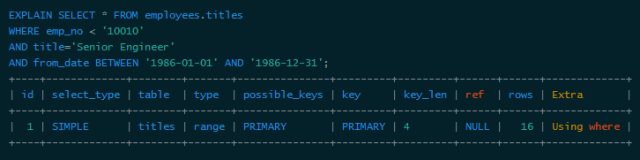
You can see that the index can't do anything with the second range index. Here is a special point to explain MySQL, that is, only using explain may not be able to distinguish between range index and multi-value matching, because both are displayed as range in type. At the same time, using "between" does not mean a range query, such as the following query:
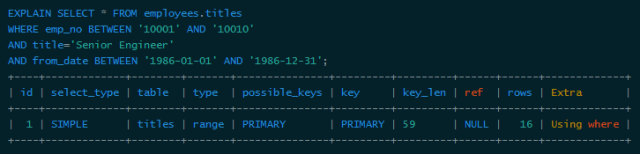
It seems that two range queries are used, but the "BETWEEN" acting on emp_no is actually equivalent to "IN", which means that emp_no is actually a multi-value exact match. You can see that this query uses all three columns of the index. Therefore, it is necessary to carefully distinguish between multi-value matching and range matching in MySQL, otherwise the behavior of MySQL will be confused.
Case 7: The query condition contains a function or expression.
Unfortunately, if the query contains a function or expression, MySQL will not use an index for this column (although some can be used in a mathematical sense). E.g:

Although this query has the same function as in case five, because the function left is used, an index cannot be applied to the title column. In case five, LIKE can be used. Another example:

Obviously, this query is equivalent to querying a function whose emp_no is 10001, but because the query condition is an expression, MySQL cannot use an index for it. It seems that MySQL is not smart enough to automatically optimize constant expressions. Therefore, when writing query statements, try to avoid expressions in the query, but first manually perform algebraic operations privately and convert them into query statements without expressions.
Index selectivity and prefix index
Since the index can speed up the query speed, should the index be built as long as the query statement requires it? the answer is negative. Although the index speeds up the query, the index has a price: the index file itself consumes storage space, and the index will increase the burden of inserting, deleting, and modifying records. In addition, MySQL also consumes resources to maintain the index when it is running. Therefore, the index is not better. Generally, it is not recommended to build an index in two cases.
The first case is that the table records are relatively small, such as a table with one to two thousand or even a few hundred records. There is no need to build an index, just let the query do a full table scan. As for how many records are counted as many, this individual has a personal opinion. My personal experience is based on 2000 as the dividing line. If the number of records does not exceed 2000, you can consider not indexing, and if you exceed 2000, you can consider indexing as appropriate.
Another situation where indexing is not recommended is the low selectivity of the index. The so-called index selectivity (Selectivity) refers to the ratio of the unique index value (also called Cardinality) to the number of table records (#T):
Index Selectivity = Cardinality / #T
Obviously the selectivity range is (0, 1], the higher the selectivity, the greater the value of the index, which is determined by the nature of B+Tree. For example, the employees.titles table used above, if the title field It is often queried separately, whether it is necessary to build an index, let's take a look at its selectivity:
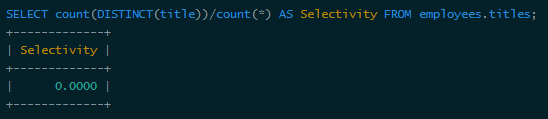
The selectivity of title is less than 0.0001 (the exact value is 0.00001579), so there is really no need to build a separate index for it.
There is an index optimization strategy related to index selectivity called prefix index, which uses the prefix of the column instead of the entire column as the index key. When the prefix length is appropriate, the selectivity of the prefix index can be close to that of the full column index. The index key becomes shorter, which reduces the size and maintenance overhead of the index file. The following takes the employees.employees table as an example to introduce the selection and use of prefix indexes.
From Figure 12 you can see that the employees table has only one index, so if we want to search for a person by name, we can only scan the entire table:

If you frequently search for employees by name, this is obviously very inefficient, so we can consider building an index. There are two options, build or, look at the selectivity of the two indexes:
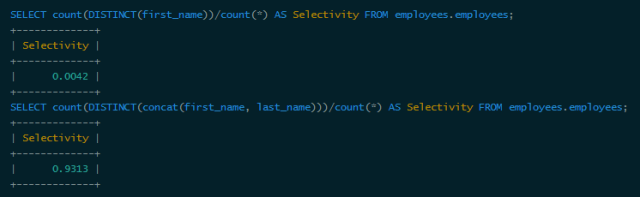
Obviously the selectivity is too low and the selectivity is very good, but the combined length of first_name and last_name is 30. Is there a way to balance length and selectivity? You can consider using the first few characters of first_name and last_name to build an index. For example, look at its selectivity:

The selectivity is not bad, but it is still a bit far from 0.9313, so add the last_name prefix to 4:

At this time, the selectivity is already ideal, and the length of this index is only 18, which is nearly half shorter than that. We build this prefix index:
ALTER TABLE employees.employees
ADD INDEX `first_name_last_name4` (first_name, last_name(4));
At this point, perform the query by name again, and compare and analyze the results before indexing:

The performance improvement is significant, and the query speed is increased by more than 120 times.
Prefix index takes into account index size and query speed, but its disadvantage is that it cannot be used for ORDER BY and GROUP BY operations, nor can it be used for covering index (that is, when the index itself contains all the data required for the query, the data file itself is no longer accessed).
InnoDB's primary key selection and insertion optimization
When using the InnoDB storage engine, if there is no special need, always use an auto-incremented field that has nothing to do with the business as the primary key.
I often see posts or blogs discussing the issue of primary key selection. Some people suggest using self-incrementing primary keys that are not business-related. Some people think it is unnecessary. You can use unique fields such as student ID or ID number as the primary key. Regardless of which argument is supported, most arguments are business-level. From the perspective of database index optimization, it is definitely a bad idea to use the InnoDB engine instead of auto-incrementing the primary key.
The index implementation of InnoDB was discussed above. InnoDB uses a clustered index, and the data record itself is stored on the leaf node of the main index (a B+Tree). This requires that the data records in the same leaf node (the size of a memory page or disk page) are stored in the order of the primary key, so whenever a new record is inserted, MySQL will insert it into the appropriate node according to its primary key And position, if the page reaches the load factor (InnoDB defaults to 15/16), then a new page (node) is opened.
If the table uses an auto-increasing primary key, every time a new record is inserted, the record will be sequentially added to the subsequent position of the current index node. When a page is full, a new page will be automatically opened. As shown below:
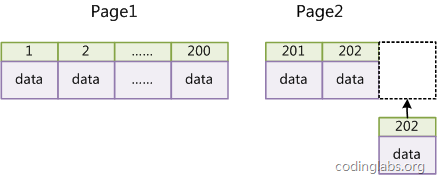
Figure 13
This will form a compact index structure, filled in approximate order. Since there is no need to move existing data every time it is inserted, it is very efficient and does not increase a lot of overhead in maintaining the index.
If you use a non-incremental primary key (such as an ID number or student number, etc.), since the value of the primary key inserted each time is approximately random, each new record must be inserted into a certain position in the middle of the existing index page:
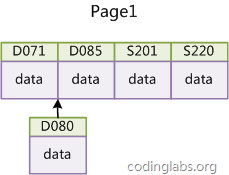
Figure 14
At this time, MySQL has to move the data in order to insert the new record into the appropriate position, and even the target page may have been written back to the disk and cleared from the cache. At this time, it must be read back from the disk, which adds a lot of overhead. At the same time, frequent movement and paging operations caused a lot of fragmentation, and an insufficiently compact index structure was obtained. Later, the table had to be rebuilt through OPTIMIZE TABLE and optimized to fill the page.
Therefore, as long as possible, please try to use auto-increment fields as primary keys on InnoDB.
postscript
This article was written intermittently for half a month, and the main content is the above. It is undeniable that this article is somewhat on paper, because my use of MySQL is a rookie level, and I don't have much experience in database tuning. It is a bit shameless to talk about database index tuning here. Think of it as my personal study notes.
其实数æ®åº“索引调优是一项技术活,ä¸èƒ½ä»…ä»…é ç†è®ºï¼Œå› 为实际情况åƒå˜ä¸‡åŒ–,而且MySQL本身å˜åœ¨å¾ˆå¤æ‚的机制,如查询优化ç–略和å„ç§å¼•æ“Žçš„实现差异ç‰éƒ½ä¼šä½¿æƒ…况å˜å¾—æ›´åŠ å¤æ‚。但åŒæ—¶è¿™äº›ç†è®ºæ˜¯ç´¢å¼•è°ƒä¼˜çš„基础,åªæœ‰åœ¨æ˜Žç™½ç†è®ºçš„基础上,æ‰èƒ½å¯¹è°ƒä¼˜ç–略进行åˆç†æŽ¨æ–并了解其背åŽçš„机制,然åŽç»“åˆå®žè·µä¸ä¸æ–的实验和摸索,从而真æ£è¾¾åˆ°é«˜æ•ˆä½¿ç”¨MySQL索引的目的。
å¦å¤–,MySQL索引åŠå…¶ä¼˜åŒ–涵盖范围éžå¸¸å¹¿ï¼Œæœ¬æ–‡åªæ˜¯æ¶‰åŠåˆ°å…¶ä¸ä¸€éƒ¨åˆ†ã€‚如与排åºï¼ˆORDER BY)相关的索引优化åŠè¦†ç›–索引(Covering index)的è¯é¢˜æœ¬æ–‡å¹¶æœªæ¶‰åŠï¼ŒåŒæ—¶é™¤B-Tree索引外MySQLè¿˜æ ¹æ®ä¸åŒå¼•æ“Žæ”¯æŒçš„哈希索引ã€å…¨æ–‡ç´¢å¼•ç‰ç‰æœ¬æ–‡ä¹Ÿå¹¶æœªæ¶‰åŠã€‚如果有机会,希望å†å¯¹æœ¬æ–‡æœªæ¶‰åŠçš„部分进行补充å§ã€‚
A manual pulse generator (MPG) is a device normally associated with computer numerically controlled machinery or other devices involved in positioning. It usually consists of a rotating knob that generates electrical pulses that are sent to an equipment controller. The controller will then move the piece of equipment a predetermined distance for each pulse.
The CNC handheld controller MPG Pendant with x1, x10, x100 selectable. It is equipped with our popular machined MPG unit, 4,5,6 axis and scale selector, emergency stop and reset button.
Manual Pulse Generator,Handwheel MPG CNC,Electric Pulse Generator,Signal Pulse Generator
Jilin Lander Intelligent Technology Co., Ltd , https://www.jilinlandermotor.com