Fusion image enhancement method and sequence optimization image captioning method
Image captions are designed to automatically generate natural language descriptions for input images. They can be used to assist people with visual impairments to perceive the surrounding environment and to help people more easily deal with large numbers of unstructured visual information. The current mainstream method is mainly based on the end-to-end training optimization of the deep encoder-decoder framework, but due to the corresponding deviations between the visual concepts and the semantic entities, the fine grained semantics of the images are not well recognized and understood in the captions. In this paper, based on this problem, the attention mechanism based on detection features and Monte Carlo sampling and the sequence optimization method based on the improved strategy gradient are proposed. The two are combined into an overall framework for image captioning.
In our method, in order to better extract the strong semantic features of the image, first use Faster R-CNN instead of the general convolutional network as the encoder; based on this, based on Monte Carlo sampling design an enhanced attention mechanism ( Reinforce Attention) to filter out the visual concepts that are worth paying attention to at the moment to achieve more precise semantic guidance. In the stage of sequence optimization, we use the discount factor and frequency-inverse document frequency (TF-IDF) factor to improve the evaluation function of the strategy gradient, so that the words with stronger semantics when generating the caption have greater reward value, and thus contribute. More gradient information to better guide sequence optimization. We mainly perform training and evaluation on the MS COCO data set. The model has achieved a significant improvement in the scores of all current authoritative metrics. Taking the CIDEr index as an example, compared with the currently representative methods [5] and [7], our model has increased 8.0% and 4.1% respectively in the final score.
The image caption aims to generate a matching natural language description for an input image. The workflow is shown in Figure 1(a) below.
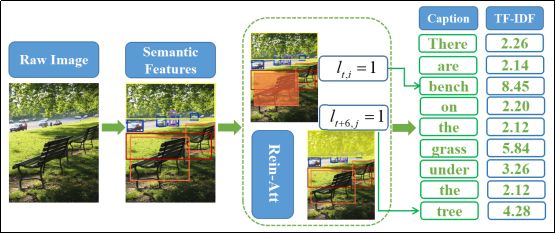
Figure 1(a) Forward Model Calculation Process
An open-field image caption is a challenging task because it requires not only a fine-grained semantic understanding of all the local and global entities in the image, but also the properties and relationships between these entities. From the academic value point of view, research in the field of image captions has greatly stimulated how the two areas of computer vision (CV) and natural language processing (NLP) are better intertwined; in the dimension of actual application, image captions The progress is crucial for building a better AI interaction system, especially for people with visual impairment to better perceive the world and to help people more easily organize and understand mass unstructured visual information, etc. On the other hand, it has great value.
Research in the field of image captioning has progressed very rapidly, and a lot of iconic work has recently taken place. At present, the attention model based on the Encoder-Decoder framework has achieved good results on all standard data sets of image captions. The visual attention model is mainly used to extract spatially significant areas for better mapping to the vocabulary to be generated. Based on this, a large number of improvements have been derived. Recently, some research efforts have been devoted to integrating bottom-up object detection and attribute prediction methods and attention mechanisms, and in evaluating the scores of indicators. Has made a good improvement. However, all of these tasks are based on Word-Level training and optimization methods. This leads to the following two questions: The first is “Exposure Bias,†which means that the model is based on the given reality (Ground- The Truth) word calculates the maximum likelihood of the next word, but in the test it needs to predict the next word based on the actual generation; the second problem is the inconsistency of the model in training and evaluation. Because the cross-entropy loss function is used in training, when assessing model generated captions, some non-differentiable metrics specific to the NLP domain are used, such as BLEU [11], ROUGE, METEOR, and so on. CIDEr and so on.
In order to solve the above problems, some recent work has innovatively introduced optimization methods based on reinforcement learning. With the aid of strategic gradients and Baseline Functions, the original word-level training is improved to a sequence-level model, which greatly compensates for the deficiency of the original scheme and improves the performance of image captions. . However, these methods also have some limitations. For example, in [5] and [10], a complete caption is generated by sampling one sequence to obtain a reward (Reward), and all the words are shared by the default gradient optimization. value. Obviously, this is unreasonable in most cases, because different words have different parts of speech, semantic emphasis, and implied significant differences in the amount of information. They should be differentiated into different Linguistic Entity and correspond in training. Visual Concepts. In order to solve these problems, we propose the following fusion annotation-enhancement mechanism and sequence optimization image captioning method.
In our method, we use Faster R-CNN instead of the general convolutional network as the encoder to extract the strong semantic feature vectors (Semantic Features) based on object detection and attribute prediction for the input image. Afterwards, we designed a Reagency Attention based on Monte Carlo sampling to filter out the visual concepts that are worth paying attention to at the moment and achieve more precise semantic entity guidance. In the Sequence Optimization phase, we use the strategy gradient method to calculate the approximate gradient of the sequence. While calculating the reward value of each sample word, we use the discount factor and term frequency-inverse document frequency (TF-IDF) factor to improve the original tactical gradient function, so that words with stronger semantics when generating the caption have more Large reward values, which contribute more gradient information for training, to better guide sequence optimization. In the experiment, our performance scores on the MS COCO dataset exceeded the current baseline method, demonstrating the validity of the method design.
Image captioning method
In general, image captioning methods can be divided into two categories: one is template-based and the other is neural network-based. The former mainly completes caption generation through a template, and the filling of this template requires output based on object detection, attribute prediction, and scene understanding. The method proposed in this paper adopts a framework that is consistent with the latter, so in the following we mainly introduce the work related to image captioning based on neural networks.
In recent years, a series of work of deep encoder-decoder loaded with visual attention mechanism has achieved very good results on various standard data sets of image captioning tasks. The core mechanism of this kind of method lies in: the convolutional network and the circular network that fuse the visual attention mechanism, can better mine the implicit contextual visual information, and train the local and global entity information fully in the end-to-end training. This provides a stronger generalization capability for caption generation. Afterwards, much of the work started from this point: on the one hand, it continued to strengthen and improve the effectiveness of the attention mechanism and put forward some new computing modules or network architecture; on the other hand, part of the work was devoted to the feature extraction and characterization methods based on the detection framework. The attention mechanism is fused together to get better physical capture capabilities.
However, there are currently two significant flaws in the Word-Level training model that uses cross-entropy based on the visual attention method: Exposure Bias and Inconsistency. In order to better solve these two problems, the optimization method based on reinforcement learning was introduced into the image caption task. Among them, the representative work is [10]. They re-modeled the problem as a strategy gradient optimization problem and used the REINFORCE algorithm to optimize. In order to reduce the variance and improve the training stability, [10] proposed a mixed increment. The training method. Subsequent work such as [5][15] made different improvements based on this. They mainly proposed a better Baseline Function to enhance the effect of sequence optimization with greater limit and more efficiency. However, one significant limitation of these current methods is that all the words in the default sentence enjoy a common reward value when sampling the sequence gradient. This is obviously unreasonable. In order to make up for this defect, we have introduced two optimization strategies: First, proceed from the calculation of the evaluation function in reinforcement learning, introduce a discount factor, and more accurately calculate the gradient value of each word sampled and returned; second, from the direct Starting from the original intention of Metric-Driven, the TF-IDF factor was introduced into the reward calculation to better exert the driving effect of the strong language entity on the overall optimization of the sequence.
method
The overall work framework of our model is shown in Figure 1, where (a) is a forward calculation flow from input to output and (b) is a sequence optimization procedure based on reinforcement learning. In the following, we will extract three aspects of semantic feature extraction, caption generator and sequence optimization, and introduce our method details in turn.
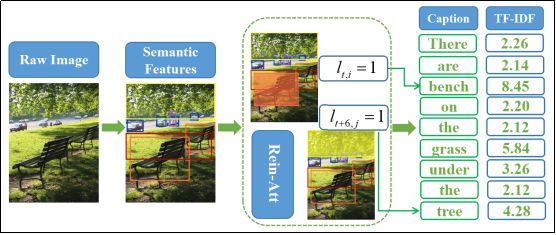
Figure 1(a) Forward Model Calculation Process
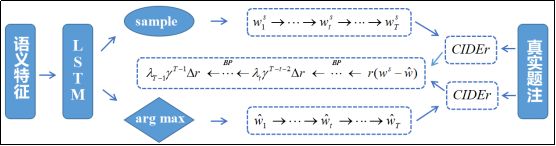
Figure 1(b) Sequence Optimization Process Based on Reinforcement Learning
1. Semantic Features
For input images, unlike common practice, we do not extract convolutional feature vectors, but instead extract the semantic feature vectors of the images based on object detection and attribute prediction, which makes it possible to better match the real captions in the training process. Language entities match. In this paper, we use Faster R-CNN [33] as the visual encoder in the image caption model. Given the input picture I, the semantic characteristics that need to be output are recorded as:
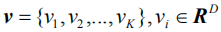
We do a Non-maximum Suppression on the final output of Faster R-CNN for each selected candidate area 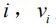
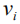
2. Caption Generator
(1) Model structure and objective function
Given an image I and the corresponding semantic feature vector 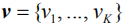
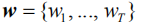
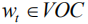
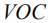
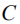
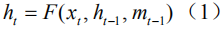
among them 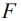
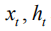
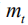
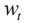
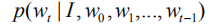
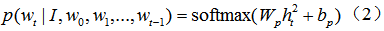
among them, 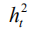

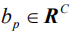
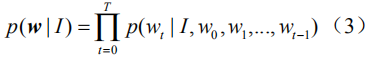
As with all previous Encoder-Decoder frameworks, the cross-entropy (XENT) loss function is used here to train and optimize the entire network, which is to find the following minimum of the objective function:
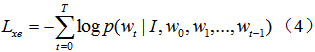
(2) Reinforcing Attention Attention Mechanism
Below we introduce two layers of LSTM input vectors 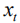
In each step of the calculation, the first layer of input 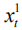
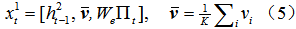
among them 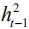
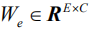
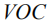
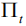
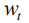
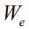
Get the output of the first layer 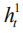
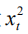
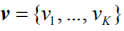
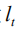
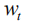
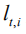
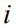
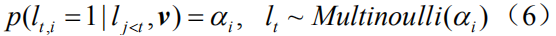
In the actual calculation, we perform Monte Carlo sampling (MC Sampling) 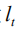
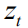
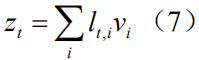
Finally we use the series operation again 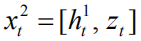
Since we used nondifferentiable Monte Carlo sampling in equation (6) above, we need to redefine a new objective function that is slightly different from equation (4). Drawing on the work in [19][29], we introduce the original objective function 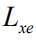
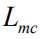
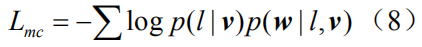
Here we use the REINFORCE algorithm [30] to approximate the calculation 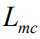
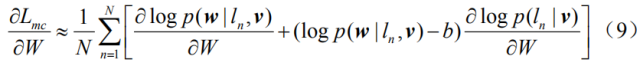
among them 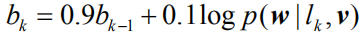
3, Sequence-Level Optimization (Sequence-Level Optimization)
In order to more directly optimize the NLP metrics and solve the problem of Exposure Bias well, we modeled the image problem focus to a new sequence-based decision problem based on reinforcement learning. We can regard the generative model described above as an agent and interact with the environment composed of images and vocabularies in real time. We define the state as: 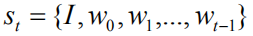
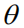
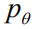
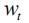
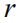
For an image caption task, this goal can be formulated as the minimum value for the negative expected bonus prize:
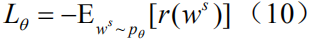
Here 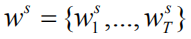
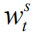
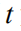
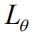
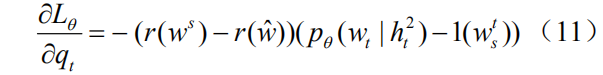
among them 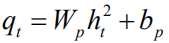
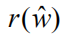
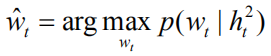
But as we mentioned in the introduction, this calculation ignores differences in the contribution of different language entities to the value of the entire sequence of rewards. Therefore we propose the following two improvements: (1) We introduce a discount factor. 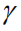
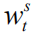
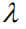
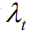
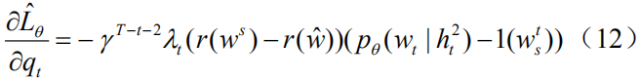
experiment
1, Datasets (Datasets)
We evaluated our proposed method in the most common dataset in the current image caption field, MS COCO [31]. The data set has a total of 123,287 pictures, and each picture has five manually annotated captions as the ground truth, in which 82,783 training sets and 40,504 verification sets are divided. The test set is another 40,775 images that are specifically used for online system assessments. The official value of the corresponding captions is not disclosed. Therefore, when the model needs to be validated and debugged offline, we use another dataset partitioning standard to divide the verification set and test set containing 5000 images from the 123297 image set. For the preprocessing of all caption statement data, including word segmentation and lexicon generation, we use the current public open source code [https://github.com/karpathy/neuraltalk] to remove infrequent vocabularies and generate a total of 9487 differences. Dictionary of words (ie 

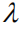
2, Implementation Details (Implementation Details)
Feature Extraction When extracting semantic features, we use a Faster R-CNN network based on ResNet-101 [32]. We set the IoU threshold to 0.7 for region candidate frame suppression (Suppression) and 0.3 for object class suppression. In order to select the significant image area, we set a detection confidence of 0.2 detection. In the experiment, we found that up to 36 significant semantic regions were selected for each image, ie 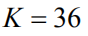
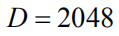
Training deployment Each LSTM hidden unit 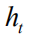
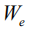
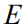
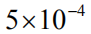
3, the results of analysis
In the local evaluation, we mainly compared the results of the model on the MS COCO data set with the following three new representative models: (1) Adaptive Attention [6], labeled AdaAtt; (2) Self-Critical Sequence Training [5], labeled SCST; (3) Bottom up and Top Down Attention [7], labeled BU-Att. The results of the comparison are shown in Table 1:
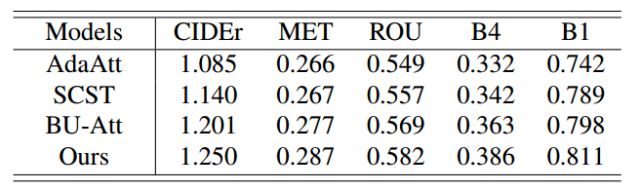
Comparison of the performance of Table 1 and other representative methods
Here we mainly record five metrics, including CIDEr, METEOR (marked MET), ROUGLE (marked ROU), BLEU-4 (marked as B-4) and BLEU-1 (marked as B-1). From this we can draw the following conclusions: (1) The method proposed by us has significantly higher scores on the evaluation indicators of image captions than the other three; (2) Four methods on each index The increase in scores are basically consistent. Taking the CIDEr score as an example, we found that from AdaAtt to BU-Att, to our method, each improvement achieved about 5 points. This can explain to a certain extent that our idea of ​​improvement is of great significance for the further progress of image captioning tasks.
In addition, we analyzed the contribution of the different components of the proposed method to image caption performance improvement: (1) First, we examine the performance gains of using only the Reinforce Attention component (marked as Reinforce); (2) After that, we separately examined our proposed sequence optimization improvement factor. 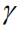
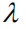
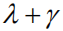
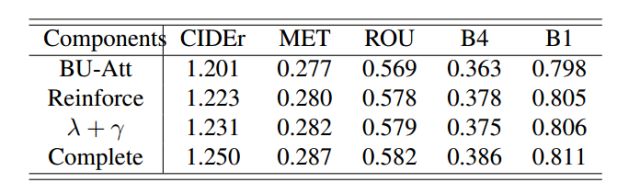
Table 2 Performance Analysis Table for Different Components of the Model
From this we can see that the two components we have improved have achieved a significant improvement in the scores of various evaluation indicators on the BU-Att basis. 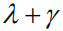

Figure 2 Image caption results visualization
(The green box in the picture indicates the result of the Reinforce Attention. The green box in the statement is the corresponding generated word.)
in conclusion
In this paper, we present an image captioning method that incorporates enhanced attention mechanisms and sequence optimization. First of all, we designed an enhanced attention mechanism based on Faster R-CNN detection features and Monte Carlo sampling; later in the sequence optimization stage, we introduced the discount factor and the TF-IDF factor to improve the evaluation function of the strategy gradient, making the generation of the caption more efficient. Strongly semantic words have greater reward values, which contribute more gradient information and better guide sequence optimization. In general, our method achieves better fine-grained semantic matching between images and statements. Through experiments on MS COCO, we verified the effectiveness of the method design.
Product categories of Maskking, we are specialized electronic cigarette manufacturers from China, Vapes For Smoking, Vape Pen Kits, E-Cigarette suppliers/factory, wholesale high-quality products of Modern E-Cigarette R & D and manufacturing, we have the perfect after-sales service and technical support. Look forward to your cooperation!
maskking e cigarette, maskking vape pen, maskking disposable vape, Maskking HIGH GT Vape, maskking vape
Ningbo Autrends International Trade Co.,Ltd. , https://www.ecigarettevapepods.com